



En este artículo mostramos cómo implementar una arquitectura de datos en Azure Databricks. Además, explicamos cuáles son los componentes de una arquitectura lakehouse y qué servicios de Microsoft usar en cada una de sus fases.
¿Qué es una arquitectura de datos lakehouse?
Una arquitectura de datos lakehouse busca integrar en un único lugar todos los datos de la organización para poder dar respuesta a las diversas necesidades de los diferentes usuarios de la información. Desde un gerente que quiere analizar las ventas del mes hasta un científico de datos que busca patrones para predecir la demanda futura.
Para lograrlo, la arquitectura lakehouse, se aprovecha del almacenamiento masivo a bajo costo en la nube del data lake y ,a través de distintas herramientas, busca proveer una interfaz para consultar los distintos tipos de datos existentes, sin importar su formato o estructura y manteniendo muchas de las propiedades de un warehouse tradicional.
La arquitectura de datos lakehouse fue ideada a partir de dos modelos:
- Data lake: Se utiliza para el almacenamiento de grandes volúmenes de datos de diversos orígenes y en distintos formatos, muchas veces sin una estructura fija como podrían ser archivos multimedia o los logs de un servidor. Esto suele generar dificultad para trabajar con estos archivos de múltiples formatos.
- DataWarehouse: En él se alojan las bases de datos estructuradas orientadas a la analítica.Se caracterizan por la fidelidad de los datos que contienen y su facilidad de acceso a través de lenguajes como SQL. Como contrapartida, el warehouse tiene problemas para trabajar con archivos no estructurados como los mencionados más arriba.
En este artículo explicamos en detalles qué son las arquitecturas de datos modernas.
¿Cuáles son los componentes de una arquitectura lakehouse?
Una arquitectura lakehouse tiene cuatro componentes o partes principales: origen de datos, almacenamiento en la nube, procesamiento de datos y consumo. Veamos en qué consiste cada una:
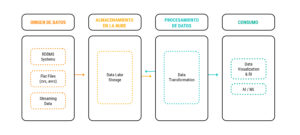 Arquitectura básica de un pipeline de datos – Lakehouse
Arquitectura básica de un pipeline de datos – Lakehouse
Origen de datos
Es donde se encuentran los datos que nos interesa procesar. La fuente puede ser muy diversa, incluyendo, por ejemplo, información de bases transaccionales (como puede ser información del sistema de ventas de una empresa, en la que se registra el monto, el cliente y la cantidad de cada venta realizada) o información en tiempo real (como pueden ser los clicks realizados en una página web o logs de un servidor).
La información que incorporamos puede ser propia (es decir, de un sistema controlado por nosotros) o externa (información que publica el gobierno o de acceso público). También es posible recibir información en forma de archivos que se pueden encontrar en diferentes formatos, como Excel, CSV, JSON, etc.
Almacenamiento en la nube
El primer paso en una arquitectura lakehouse es llevar los datos desde los diversos orígenes a un almacenamiento de objetos en la nube. Con esto buscamos tener toda la información centralizada en un único lugar. Es importante que sirva como punto de acceso a cualquier información de la organización y que mantenga la historia de los datos.
Por lo general en esta etapa, se suelen almacenar tal cual existen en el origen, sin modificarlos. Esto permite tener los datos originales en caso de ser necesario —aprovechando que el costo de almacenamiento en la nube es considerablemente bajo—, lo que nos garantiza mantener registros antiguos que podrían ser eliminados en los orígenes.
Procesamiento
En esta etapa se lleva a cabo la transformación de los datos. Buscamos:
- En primer lugar, depurar los datos crudos como se reciben en el origen, eliminando inconsistencias, consolidarlos y estandarizarlos en un formato que sea similar para todos. Esto nos va a permitir trabajar con mayor facilidad y con datos más confiables.
- En segundo lugar, se pueden aplicar reglas y lógicas de negocio sobre los distintos datos que se obtuvieron. De esta manera, damos lugar a información ordenada, de forma estructurada para dar soporte a las diversas necesidades de información.
Durante esta etapa, los datos se procesan y vuelven a ser escritos en el mismo almacenamiento de la nube. La información puede terminar en un data warehouse o no, esto dependerá de la necesidad
Como veremos más adelante, es en esta etapa donde Azure Databricks va a cobrar mayor protagonismo.
Consumo de datos
Esta etapa es la que justifica todos los pasos previos que realizamos. Los usuarios van a conectarse a los datos para realizar las consultas necesarias que faciliten la toma de decisiones.
En general, podemos agrupar el tipo de consumo de datos en cuatro categorías:
- Herramientas de visualización: Se conecta algún software de visualización (PowerBI, Tableau) de datos al data lake para generar tableros con la información procesada.
- Consultas a demanda (ad hoc): Esto sucede cuando algún usuario puede tener una consulta particular que necesite ejecutar sobre los datos, pero al ser de única vez no se justifica la elaboración de un tablero. Por ejemplo, un usuario que, ante consulta de algún directivo, necesita conocer los datos de contacto de un cliente particular, para lo cual ejecuta la consulta por única vez.
- Ciencia de datos: Hay usuarios que necesitan trabajar con los datos para elaborar y/o entrenar sus modelos de inteligencia artificial. Estos usuarios suelen beneficiarse de los datos crudos (tal cual se reciben de los orígenes), ya que muchos modelos requieren la mayor cantidad de información posible para mejorar su precisión o capacidad predictiva.
- Otros servicios/aplicaciones: Cada vez es más frecuente que los datos generados y almacenados en el data lake necesiten ser consumidos por otros procesos para ingestar la información en diversos sistemas (esto puede darse incluso en tiempo real). Generalmente esto se cubre mediante el desarrollo de APIs que permitan disponibilizar los datos a terceros.
Por ejemplo, una organización podría conectar su CRM al lakehouse a través de una API para actualizar los datos de sus clientes en base al resultado de un modelo ejecutado en el lakehouse.
Arquitecturas lakehouse: ¿por qué es importante el desacoplamiento?
Desacoplar implica mantener la independencia entre los datos propiamente dichos y el motor o la herramienta que los procesa. El desacoplamiento entre almacenamiento y procesamiento es un punto clave de una arquitectura de lakehouse por varios motivos:
- Persistencia de los datos por fuera del sistema de procesamiento, ante fallos en el software de procesamiento, los datos se mantienen intactos y no hace falta ningún proceso para recuperarlos.
- Permite escalar cualquiera de los dos sin afectar al otro, de esta manera podemos tener una mayor cantidad de datos almacenados manteniendo la capacidad de procesamiento constante, o viceversa. Esto asegura un mejor manejo y optimización de los costos en la nube.
- Flexibilidad para migrar una herramienta o tecnología, si en un futuro necesitamos cambiar el software utilizado para procesar los datos, podemos hacerlo de forma sencilla sin necesidad de afectar en lo más mínimo el almacenamiento de los datos. Solo se necesita un pequeño ajuste para apuntar la nueva herramienta a nuestro almacenamiento en la nube.
A continuación, explicaremos cómo implementar todo esto en Azure Databricks.
¿Cómo implementar una arquitectura lakehouse con Azure Databricks?
Una vez introducidos los conceptos básicos de nuestra arquitectura, llegó el momento de colocar nombres dentro de este esquema y de ver dónde entra Azure Databricks (en este artículo explicamos en qué consiste esta plataforma). En el siguiente diagrama, podemos ver cómo es una arquitectura estándar sencilla que podríamos implementar en la nube de Azure, utilizando algunos de sus servicios y Databricks:
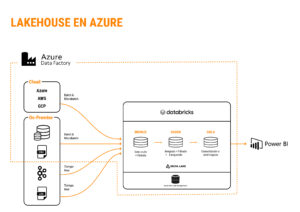
Lakehouse en Azure
Azure Data Factory (ADF)
En esta arquitectura modelo, el primer servicio que vamos a mencionar es Azure Data Factory. Posibilita armar pipelines de datos mediante una interfaz gráfica del tipo Drag and Drop que permite un desarrollo rápido, ya que cuenta con varias actividades preconfiguradas que facilitan las conexiones y la relación con los otros servicios.
Este servicio servirá en particular para dos elementos claves del pipeline:
- Orquestación: A través de ADF podremos orquestar la ejecución de nuestros pipelines de datos. Establecemos la ejecución a través de triggers que se pueden configurar para que ejecuten con la frecuencia que necesitemos (se pueden elegir una o varias horas y/o días específicos). La ejecución desde ADF se encargará de llamar a la ingesta de datos y a los diferentes servicios que sean necesarios durante el proceso, entre ellos Azure Databricks.
- Ingesta: ADF también nos va a permitir realizar la ingesta de datos de los diversos orígenes. Cuenta con diversos conectores ya configurados que permitirán conectar con el origen mediante simples pasos, colocando la información de origen y las credenciales necesarias. Algunos de los que se pueden conectar a través de ADF son: Oracle, SQL Server, SAP, Salesforce, FTP, etc.
Para la conexión con los diferentes orígenes ADF posee la funcionalidad de “Integration Runtime”, que es el entorno de ejecución que hace de intermediario entre el origen y la nube, facilitando la ingesta de datos desde las bases on-premise. Por defecto este servicio es administrado por Azure, pero podemos elegir instalar el componente en un servidor local, lo que permite una mejor gestión de seguridad al centralizar el punto de transmisión de los datos en un único lugar.
Azure Data Lake Storage
Será el encargado del almacenamiento. Para esto utilizaremos Azure Data Lake Storage Gen2, que es un servicio de almacenamiento por objetos, en el que vamos a guardar todos los datos ingestados y procesados. Tiene una capacidad virtualmente ilimitada y abonaremos un costo bajo por el tamaño de los datos que guardemos. Como mencionamos, Azure Databricks podrá conectarse a este servicio para realizar la lectura y posterior escritura de los datos.
Azure Databricks
Este servicio participa de la etapa de procesamiento. Recibe los datos crudos ingestados por Data Factory y realiza las distintas operaciones y transformaciones necesarias sobre los mismos.
¿Cómo trabajar con Azure Databricks?
Azure Databricks es un servicio de procesamiento distribuido que se basa en Spark. Para trabajar se elaboran notebooks que pueden contener diversos lenguajes de programación, entre los que se encuentra Python (con PySpark), Scala, R y SQL. Azure Databricks se encarga de ejecutar nuestro código sobre el cluster, traduciendo los comandos a Spark cuando sea necesario.
A través de Databricks nos conectaremos al almacenamiento de Azure, leyendo los datos del Data Lake Storage, ejecutando nuestro código (que realizará las transformaciones y procedimientos que necesitemos) y luego volveremos a guardar los datos ya terminados también en el data lake. De esta manera se mantiene la separación entre almacenamiento y procesamiento de los datos.
También recomendamos generar tablas en Azure Databricks, haciendo referencia a nuestros datos. Esto permite manejar, de forma mucho más sencilla su acceso y gestionar la seguridad de qué usuario puede verlos. A través de estas tablas podremos ver los diversos campos que contienen, de la misma forma que podríamos ver una tabla de datos en una base relacional (en columnas y filas).
En este punto, hay que tener en cuenta que Azure Databricks no es una base de datos tradicional, sino que es un motor que trabaja con archivos. De esta manera, si bien podemos generar tablas que contengan datos en forma de una clásica tabla relacional, al fin y al cabo, lo que almacenamos en el Data Lake Storage serán archivos.
Esto otorga flexibilidad a Azure Databricks, ya que permite trabajar con múltiples tipos de formato (archivos de texto plano, CSV, JSON y también con archivos orientados al consumo analítico como Parquet, ORC o AVRO, formatos muy comunes al trabajar en entornos distribuidos) y hacerlo como si fueran tablas relacionales. Databricks se encarga de la lectura y de la adaptación de la estructura por nosotros.
Consumo
PowerBI: Interviene en la etapa de consumo de los datos. Es la herramienta de visualización de Microsoft que permite realizar tableros y reportes con los datos procesados. PowerBI permite conectar los datos a través de Azure Databricks (lo que nos permitirá gestionar la seguridad de una forma mucho más estricta) o incluso leerlos directamente de Data Lake Storage.
Esta herramienta facilita compartir con toda la organización el reporte creado y automatizar su actualización. Una vez procesados los nuevos datos por el pipeline, el reporte se refresca y muestra la información actualizada, facilitando el consumo por parte de quienes la necesiten.
Conclusiones
- Azure Databricks es una plataforma como servicio (PaaS) enfocada en el procesamiento de datos con Spark en la nube, a través de un motor que permite escribir el código en diferentes lenguajes.
- Es un producto central en las arquitecturas modernas de datos. Cobra cada día más importancia en el mercado, en particular en la arquitectura lakehouse.
- Es parte del ecosistema de nube de Azure. Tiene muchas integraciones con los diferentes servicios de Azure, lo que lo hace un producto ideal para quienes ya trabajan con esta plataforma y desean ampliarse hacia el área de datos.
- Si bien en la actualidad es necesario combinarlo con varios servicios y productos diferentes dentro de una arquitectura de datos, para un pipeline sencillo de pocos orígenes puede llegar a ser suficiente el uso por completo de Azure Databricks, combinando con algún servicio de almacenamiento de datos en la nube.
- Es un producto que suma funcionalidades día a día. Databricks tiene como objetivo ser una solución completa para una problemática de datos, por lo que no se descarta que a futuro pueda cubrir más y más de una arquitectura de datos.



