



In this article we show how to implement a data architecture in Azure Databricks. Additionally, we explain what the components of a lakehouse architecture are and which Microsoft services to use in each of its phases.
What is a lakehouse data architecture?
A data lakehouse architecture seeks to integrate all of an organization’s data into a single location to address the diverse needs of different information users, from a manager analyzing monthly sales to a data scientist looking for patterns to predict future demand.
To achieve this, the lakehouse architecture leverages low-cost massive storage in the cloud of the data lake and, through various tools, aims to provide an interface to query the different types of existing data, regardless of their format or structure, while maintaining many properties of a traditional warehouse.
The data lakehouse architecture was conceived from two models:
- Data lake: Used for storing large volumes of data from various sources and in different formats, often without a fixed structure such as multimedia files or server logs. This often creates difficulties in working with these files of multiple formats.
- Warehouse: Where structured databases oriented towards analytics are housed. They are characterized by the fidelity of the data they contain and their ease of access through languages like SQL. Conversely, the warehouse struggles to work with unstructured files like those mentioned above.
In this article, we explain in detail what modern data architectures are.
What are the components of a lakehouse architecture?
A lakehouse architecture has four main components or parts: data source, cloud storage, data processing, and consumption. Let’s see what each one consists of:
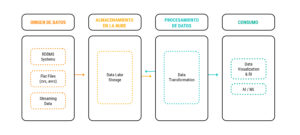
Basic architecture of a data pipeline – Lakehouse
Data Source
This is where the data we want to process is located. The source can be quite diverse, including, for example, information from transactional databases (such as sales system data from a company, which records the amount, customer, and quantity of each sale made) or real-time information (such as clicks on a website or server logs).
The information we incorporate can be proprietary (from a system controlled by us) or external (information published by the government or publicly available). It is also possible to receive information in the form of files that may be in different formats, such as Excel, CSV, JSON, etc.
Cloud Storage
The first step in a lakehouse architecture is to bring the data from various sources to cloud object storage. With this, we aim to have all the information centralized in one place. It is important that it serves as a point of access to any organization’s information and that it maintains the data’s history.
Generally, at this stage, the data is usually stored as it exists in the source, without modification. This allows us to have the original data in case it is needed — taking advantage of the fact that the cost of cloud storage is considerably low —, ensuring that we maintain old records that could be deleted at the sources.
Processing
In this stage, data transformation takes place. We aim to:
- Firstly, clean up the raw data as received from the source, eliminating inconsistencies, consolidating them, and standardizing them into a format that is similar for all. This will allow us to work more easily and with more reliable data.
- Secondly, business rules and logic can be applied to the different data obtained. This way, we create ordered information, in a structured manner to support various information needs.
During this stage, the data is processed and rewritten in the same cloud storage. The information may end up in a data warehouse or not, depending on the need.
As we will see later, it is in this stage where Azure Databricks will play a more prominent role.
Data Consumption
This stage justifies all the previous steps we’ve taken. Users will connect to the data to perform the necessary queries to facilitate decision-making.
In general, we can group the type of data consumption into four categories:
- Visualization Tools: Data visualization software (such as PowerBI, Tableau) connects to the data lake to generate dashboards with processed information.
- On-demand Queries (ad hoc): This occurs when a user may have a particular query that needs to be executed on the data, but as it is a one-time query, creating a dashboard is not justified. For example, a user who, in response to an executive inquiry, needs to know the contact information of a particular client, executes the query only once.
- Data Science: Some users need to work with the data to develop and/or train their artificial intelligence models. These users often benefit from raw data (as received from the sources), as many models require as much information as possible to improve their accuracy or predictive capability.
- Other Services/Applications: It is increasingly common for data generated and stored in the data lake to need to be consumed by other processes to ingest information into various systems (this can even occur in real-time). Generally, this is covered by developing APIs that allow data to be made available to third parties.
For example, an organization could connect its CRM to the lakehouse via an API to update customer data based on the result of a model executed in the lakehouse.
Lakehouse architectures: Why is decoupling important?
Decoupling involves maintaining independence between the data itself and the engine or tool that processes it. Decoupling between storage and processing is a key point of a lakehouse architecture for several reasons:
- Data persistence outside the processing system: In the event of failures in the processing software, the data remains intact, and no process is needed to recover it.
- Allows scaling either without affecting the other: This way, we can have a larger amount of stored data while maintaining constant processing capacity, or vice versa. This ensures better management and optimization of costs in the cloud.
- Flexibility to migrate a tool or technology: If in the future we need to change the software used to process the data, we can do so easily without affecting the storage of the data in the slightest. Only a small adjustment is needed to point the new tool to our cloud storage.
Next, we will explain how to implement all this in Azure Databricks.
How to implement a lakehouse architecture with Azure Databricks?
Now that we’ve introduced the basic concepts of our architecture, it’s time to put names within this scheme and see where Azure Databricks fits in (in this article we explain what is this platform). In the following diagram, we can see what a simple standard architecture might look like that we could implement in the Azure cloud, using some of its services and Databricks:
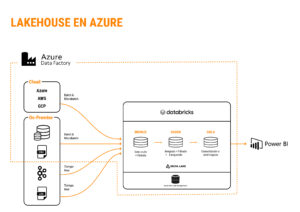
Lakehouse on Azure
Azure Data Factory (ADF)
In this model architecture, the first service we’ll mention is Azure Data Factory. It enables building data pipelines through a drag-and-drop graphical interface that allows for rapid development, as it includes various pre-configured activities that facilitate connections and interaction with other services.
This service will particularly serve two key elements of the pipeline:
- Orchestration: Through ADF, we can orchestrate the execution of our data pipelines. We establish execution through triggers that can be configured to run at the frequency we need (choosing specific hours and/or days). The execution from ADF will be responsible for triggering data ingestion and the different services required during the process, including Azure Databricks.
- Ingestion: ADF also allows us to perform data ingestion from various sources. It comes with various pre-configured connectors that enable connection with the source through simple steps, inputting source information and necessary credentials. Some sources that can be connected through ADF include: Oracle, SQL Server, SAP, Salesforce, FTP, etc.
For connection with different sources, ADF has the functionality of “Integration Runtime“, which is the execution environment acting as an intermediary between the source and the cloud, facilitating data ingestion from on-premise databases. By default, this service is managed by Azure, but we can choose to install the component on a local server, enabling better security management by centralizing the data transmission point in one place.
Azure Data Lake Storage
This will be responsible for storage. We will use Azure Data Lake Storage Gen2, which is an object storage service where we will store all ingested and processed data. It has virtually unlimited capacity, and we’ll pay a low cost based on the size of the data stored. As mentioned, Azure Databricks can connect to this service to read and write data.
Azure Databricks
This service participates in the processing stage. It receives the raw data ingested by Data Factory and performs various operations and transformations on them.
To work with Azure Databricks
Azure Databricks is a distributed processing service based on Spark. Notebooks are created to work, which can contain various programming languages, including Python (with PySpark), Scala, R, and SQL. Azure Databricks handles executing our code on the cluster, translating commands to Spark when necessary.
Through Databricks, we connect to Azure storage, reading data from Data Lake Storage, executing our code (which performs the necessary transformations and procedures), and then saving the finished data back to the data lake. This maintains the separation we mentioned between storage and data processing.
We also recommend generating tables in Azure Databricks, referencing our data. This allows for much easier management of access and security for which user can view them. Through these tables, we can have a view of the various fields they contain, similar to how we would view a data table in a relational database (in columns and rows).
At this point, it’s important to note that Azure Databricks is not a traditional database but an engine that works with files. Thus, while we can generate tables containing data in the form of a classic relational table, ultimately, what we store in Data Lake Storage are files.
This provides flexibility to Azure Databricks, allowing us to work with multiple types of formats (such as plain text files, CSV, JSON, and analytical consumption-oriented files like Parquet, ORC, or AVRO, which are very common formats when working in distributed environments) and to do so as if they were relational tables. Databricks handles the reading and structure adaptation for us.
Consumption
Power BI: It plays a role in the data consumption stage. It is Microsoft’s visualization tool that allows creating dashboards and reports with processed data. Power BI enables connecting data through Azure Databricks (which allows us to manage security in a much stricter way) or even reading them directly from Data Lake Storage.
This tool facilitates sharing the created report with the entire organization and automating its update. Once the new data is processed by the pipeline, the report is refreshed and displays the updated information, facilitating consumption by those who need it.
Conclusions
- Azure Databricks is a platform as a service (PaaS) focused on cloud-based data processing with Spark, allowing code to be written in different languages.
- It is a central product in modern data architectures and is gaining increasing importance in the market, particularly in lakehouse architectures.
- It is part of the Azure cloud ecosystem and has many integrations with various Azure services, making it an ideal product for those already working with this platform and looking to expand into the data area.
- While it is currently necessary to combine it with various services and products within a data architecture, for a simple pipeline with few sources, the complete use of Azure Databricks combined with a cloud data storage service may be sufficient.
- It is a product that adds functionalities day by day. Databricks aims to be a complete solution for data problems, so it is not ruled out that it may cover more and more aspects of a data architecture in the future.
—
This article was originally written in Spanish and translated into English by ChatGPT.



