



In this article, we explain in detail what a data lake is, its advantages, and disadvantages. Additionally, we describe how these types of architectures are composed and what happens in each of their layers.
Data lake: historical context
In the early 21st century, new types of data began to emerge in ever-increasing volumes. We started seeing web-based business transactions, real-time streams, sensor data, social media data, and many other new types of data that had enormous potential for exploitation.
With this abundance available, it became clear that new modern data architectures were needed to store and analyze large amounts of semi-structured data (those with flexible structures, like JSON or XML files) and unstructured data (those without a defined structure, such as videos, images, social media comments, etc.) in order to gain insights that could be used to make better business decisions.
What are the problems with the data warehouse?
Before the emergence of the data lake, traditional data architectures were primarily focused on the concept of a data warehouse (we explain this in detail in another article). However, despite its many advantages, this architecture also faced some criticism. Two of the main ones were:
- Rigidity: The limited flexibility of complex and static data models can represent a significant limitation. In a data warehouse, the model is established before data loading, which means it may struggle to handle unstructured data or data prone to frequent changes.
- Difficulty in real-time data processing: While data warehouses are designed to support batch processing, this feature may be less efficient in scenarios requiring fast, real-time processing.
These criticisms highlighted the need to evolve traditional approaches to more effectively address new challenges such as implementing data science, machine learning, artificial intelligence, and any technology that could better leverage these large volumes of data.
This context led to the rise of a modern enterprise data management scheme known as the data lake.
What is a data lake?
A data lake is a centralized storage repository that allows the storage of raw, unprocessed data in its original format. This includes unstructured, semi-structured, or structured data at scale.
A data lake is built in distributed environments and helps businesses make better commercial decisions through visualizations or other forms of analysis, such as machine learning and real-time analytics.
The idea of a data lake was first mentioned in 2010 by Pentaho’s CTO, Jame Dixon: “While a data warehouse is like a clean, bottled water ready for consumption, a data lake is considered like an entire lake of data in a more natural state.”
How is data stored in the data lake?
A data lake stores data in its original and raw form. Unlike what happens in a data warehouse, in this case, the data is saved without undergoing any type of transformation.
Data in a data lake can vary drastically in size and structure.
A data lake can store very small or enormous amounts of data, depending on the need. All these features provide flexibility and scalability, meaning it is an architecture that adapts to storing all types of data and can easily grow as the volume of information increases.
What are the advantages of a data lake?
The flexibility of a data lake allows organizations to adjust its scale according to their specific needs by separating storage from the computational part. This strategy eliminates the need for complex data transformations and preprocessing, which are typically characteristic of data warehouses.
Both data warehouses and data lakes are centralized data repositories. However, they differ in their storage capacity, which may be limited in a data warehouse, and in their processing methods.
Additionally, these are some of its main advantages:
- It solves two of the main problems posed by the data warehouse: information loss and slow response time.
- It has unlimited storage capacity because it can be built on distributed environments (Spark, Databricks) or in cloud environments (Azure, AWS, GCP).
- The ability to handle unstructured data.
- The ability to process data in real-time.
From ETL to ELT
Data warehouse approaches follow the traditional ETL process. First, the data is extracted (E) from the operational databases. Then, the data is processed, cleaned, and transformed (T) before being loaded (L) into predefined structures. Data warehouses are specifically designed to handle read-intensive workloads for analysis. They require defining their schema in advance before loading the data, a schema-on-write approach.
On the other hand, data lakes change the order of data processing. They store data in its original format without preprocessing until it is required by the application or at query time.
This approach challenges the traditional ETL rules of data warehouses, promoting the idea of ELT (Extract, Load, Transform) as a shift in the data processing order.
Data lakes do not have a predefined data schema, transforming the data into the appropriate form only when required and requested by the application for querying, using metadata. This approach is known as schema-on-read, avoiding costly data pre-transformation and performing transformation operations only when the data is read from the data lake.
What are the disadvantages of a data lake?
Working with a data lake also brings challenges related to its implementation and data analysis. Just like the data warehouse, this architecture has received criticism. Some of the main disadvantages are:
- It is technologically more complex to build.
- It focuses more on loading data rather than on consumption, which is where the real value lies.
- It often becomes a data dump rather than an information repository because the latter needs to be structured to be consumable.
- It increases complexity and decreases performance, which impacts productivity as teams end up working more in isolation.
What does a data lake-based architecture look like?
It is important to clarify that a data lake does not replace a data warehouse but rather reimagines it; these are architectures that complement each other.
Let’s look at how an architecture combining these layers is composed:
1st Layer – Data lake: This is where we store the entire history. Here, the raw data is kept, either structured or unstructured.
2nd Layer – Sandbox: In this layer, the data is partially cleaned and is where we start transforming it.
3rd Layer – Traditional data warehouse: The data is structured and of the necessary quality for use by business users.

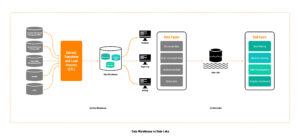
Data lake architecture
Considering this division, here is the data loading process in a data lake:
1st Layer – Data lake: Once the data consumption method is defined (batch, micro-batch, or real-time), through an engineering process, we access the different sources and store the data in the data lake. Only data engineers and architects have access to this layer.
2nd Layer – Sandbox: This can be divided into an analytical sandbox (where exploratory models and predictive analyses are conducted, and data scientists work) and an operational sandbox (where transformations are carried out, and engineering teams work).
3rd Layer – Data warehouse: Here, the models are prepared to be made available in reports or dashboards. This layer is ready for business users to access and use.
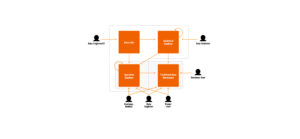
Data lake architecture – Layers and users
Conclusion
The data lake was designed with a specific purpose: to address all the information needs of an organization. However, as we have explained, its implementation is complex—it requires multiple tools for deployment, which presents challenges for data governance—and there is a risk that it could turn into a data dump, as it does not focus on data usage.
To address this issue, a new type of architecture called the Data Lakehouse was created.
—
This article was originally written in Spanish and translated into English with ChatGPT.



