



In this article, we explain the 5 features that need to be understood to get started with Databricks. We also delve into what Databricks is and how it works, what lakehouse architectures are, and the kinds of problems they aim to solve. Finally, we explain how to use Databricks Community, the free version to begin testing the platform.
What is Databricks and how does it work?
Databricks is a tool that significantly simplifies the tasks of those working in data & AI by integrating all data needs into a single solution. Instead of implementing a service for each requirement (engineering, data science, artificial intelligence, machine learning, traditional business intelligence, data governance, streaming, etc.), Databricks consolidates all the work in one place.
To operate, it uses distributed processing, a set of machines that work in a coordinated manner as if they were one. We could think of them as an orchestra where different instruments harmoniously sound as a whole.
Distributed systems date back to the 1960s; however, it was in 2009 that the Spark project emerged with the goal of addressing the limitations of data storage and computing capacity, both highly restricted at the time.
In data & analytics today, working with distributed systems is a standard because it is the only way we have to scale and process infinite volumes of data in a cost-effective manner.
Lakehouse: What is it and what problems does it solve?
The lakehouse architecture is the evolution of the data lake, understood as a repository of raw data. Unlike the latter, the lakehouse is a paradigm that incorporates technologies giving it the ability to behave like a database (transactions, updates, etc.) and ensures improvements in response times when executing SQL queries.
Lakehouse is a concept introduced by Databricks, aiming to address historical issues faced by both the data lake and the data warehouse. The lakehouse architecture combines the cost-effective storage strategy and flexibility of the data lake with the performance and availability of quality data from the data warehouse.
Data is centralized in the lakehouse and used directly from there. Regardless of the goal, whether it’s data science, marketing, or engineering, this architecture aims to meet the data needs of all individuals. Its main advantages include:
- Eliminates complexity associated with the use of multiple technologies.
- Centralizes data in one place.
- Is scalable, cost-effective, and flexible.
- Centralizes all data activities, regardless of the individual’s profile.
- Supports ACID transactions (Atomicity, Consistency, Isolation, and Durability).
This is possible because it leverages distributed systems.
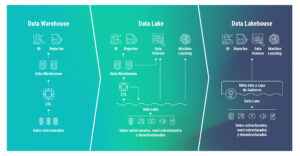
Source: Databricks
5 Features to know when getting started with Databricks
The five main features that those who are beginning to explore this tool need to know are:
1. Databricks utilizes Spark (open source) as its processing engine:
The company was founded by Spark’s creators, influencing its development. Databricks has also contributed to other significant projects in the data ecosystem, such as MLflow or the Delta format, which are open to the community, mitigating concerns about vendor lock-in.
2. Databricks is only offered as a cloud service:
It cannot be installed on-premise but currently supports major cloud platforms (Microsoft Azure, AWS, GCP, etc.) and can be used in multi-cloud setups.
Creating a cluster in Databricks is straightforward, saving the complexity associated with Spark cluster administration. Platform-as-a-Service (PaaS) allows for learning and working in a simplified manner, focusing on the value-added aspects like data processing.
3. Free practice is available:
The Databricks Community version addresses a key barrier for distributed systems— the inability to be tested.
Users can sign up for Databricks Community and access the entire Databricks front-end, providing an opportunity to try out the main features. This version is designed for practice and learning, enabling the creation of free Databricks clusters for experimentation.
4. Databricks caters to any data profile:
It is suitable for engineers, data scientists, business analysts, etc. Databricks, as a Platform-as-a-Service solution, relies on Apache Spark, allowing work via notebooks using SQL, Python, R, Scala, etc.
Anyone familiar with SQL can work with Databricks.
5. It is also for business users:
Databricks allows integration with any visualization tool (Power BI, Tableau, MicroStrategy). Regardless of the user’s profile, the platform can be utilized for work.
Databricks integrates Redash, enabling SQL queries to various database engines, facilitating the creation of custom dashboards.
In conclusion
- Databricks simplifies the data tools stack by centralizing access, manipulation, and management of data.
- It supports both batch and streaming processing.
- Incorporates Delta Live Tables for building reliable, maintainable, and testable data pipelines.
- Includes Unity, a Data Governance solution for cataloging data, automatic lineage, and centralized security management.
- Incorporates artificial intelligence with Dolly, an open-source Large Language Model (LLM).
- Databricks is a comprehensive platform covering various data & AI topics, including cloud, distributed systems, Spark, and general data processing.
- While Databricks is aspirational for data professionals, it introduces cultural changes in how tasks are performed.
***
The original version of this article was written in Spanish and translated into English by ChatGPT.



