



En este artículo explicamos qué es una arquitecturas de datos moderna, cuáles son sus capas y sus componentes y analizamos los pros y los contras del data warehouse y del data lake.
¿Qué es una arquitectura de datos?
Una arquitectura de datos es una combinación de tecnologías que permite resolver las necesidades de información de una organización. Por ejemplo: cuánto se vendió, cuántos clientes se ganaron o están en riesgo de perderse, cuál es el nivel de stock de productos, etc. Provee todos aquellos datos que el negocio necesita para poder tomar decisiones data-driven.
La arquitectura de datos es la estructura tecnológica que está detrás de una solución de datos, ya sean tableros, reportes, sistemas de alertado, modelos de inteligencia artificial, etc. Lo más importante es que pueda garantizar una visión integral del negocio.
Componentes y beneficios de una arquitectura de datos
Una arquitectura de datos tiene cuatro componentes principales:
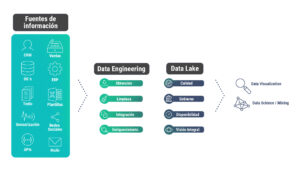
Componentes de una arquitectura de datos
- Las fuentes de información (o datos de origen): Es todo aquello que puede almacenar o generar datos. Provienen de diferentes lugares y pueden ser estructuradas (hojas de cálculo, CRM, ventas, bases de datos) y/o no estructuradas (redes sociales, mails, videos, imágenes, APIs de terceros, etc.)
- La capa de ingeniería de datos: La ingeniería de datos es la disciplina que se encarga de obtener, limpiar, integrar y enriquecer los datos para habilitar cualquier tipo de análisis posterior. Esta etapa, que también se conoce como capa de ETL (Extract, transform and load), es crítica en todo el proceso y ocupa el 80% del tiempo de los proyectos de analytics.
- El almacenamiento: Es el lugar en el que se guardan los datos —puede ser un data warehouse, un data lake o un lakehouse. Este repositorio garantiza la visión integral, la disponibilidad, la calidad y el gobierno de los datos. Si esto no sucede, lamentablemente la arquitectura de datos no va a servirle al negocio.
- El consumo: Puede ser visual (a través de tableros, reportes, alertas) o analítico (ciencia de datos, machine learning) y es lo que garantiza que las personas de la organización puedan tomar decisiones a partir de los datos. Además, se puede realizar el consumo de otros sistemas a través de APIs.
Los beneficios de desarrollar una buena arquitectura de datos son:
- Lograr una visión única de la realidad, integrando las distintas fuentes de información necesarias.
- Garantizar la disponibilidad y la calidad de la información.
- Monopolizar el acceso a la información brindando un Service Level Agreement (SLA) razonable. Esto significa que toda la organización consuma la información desde un único repositorio, en lugar de hacerlo a partir de diferentes planillas de Excel, por ejemplo.
- Gobierno de datos para garantizar seguridad, consumo, regulaciones (GDPR) y compliance.
- Alimentar todos los sistemas de información recurrentes.
Data warehouse: pros y contras
El data warehouse es el lugar en el que se almacena la información proveniente de diferentes fuentes, previa trasformación mediante un proceso de extracción, transformación y carga (ETL). Esto garantiza el consumo de los datos por parte del negocio.
Las principales ventajas de contar con un data warehouse son:
- Permite satisfacer la gran mayoría de necesidades de datos ya que da respuesta a cualquier pedido de información estructurado (tableros, reportes, etc.)
- Está orientado a temas, es decir, los datos están organizados de manera que todos los elementos relativos al mismo evento u objeto del mundo real queden unidos entre sí.
- Es integrado: La base de datos contiene los datos de todos los sistemas de la organización. Por lo que dichos datos deben ser consistentes.
- Es variante en el tiempo: Los cambios producidos en los datos a lo largo del tiempo, quedan registrados para que los informes que se puedan generar reflejen esas variaciones.
- No es volátil: La información no se modifica ni se elimina, una vez almacenado un dato, éste se convierte en información de sólo lectura, y se mantiene para futuras consultas.
Sin embargo, en la práctica el almacenamiento de datos en un data warehouse también presupone algunos problemas.
- Se puede volver un cuello de botella a medida que aumentan los orígenes de datos y no de abasto en procesarlos.
- Puede llegar a perder información en caso que el negocio demande datos que en un principio no fueron modelados.
- Está preparado para trabajar con información estática, no con esquemas de tiempo real, ni con información no estructurada (como videos, imágenes, redes sociales, etc.)
- No soporta equipos de ciencia de datos ni machine learning ya que no tiene el detalle necesario para entrenarlos.
Entonces, podríamos decir que el data warehouse deja sin resolver muchas de las necesidades de algunos equipos dentro de la organización.
Data lake: pros y contras
Es un repositorio de datos crudos, en cual los datos se almacenan tal como están en el origen. A diferencia de lo que sucede en el data warehouse, los datos en el data lake, se guardan sin hacerles ningún tipo de transformación.
Las ventajas de contar con un data lake son:
- Resuelve dos de los principales problemas que planteó el data warehouse: pérdida de información y lentitud para reaccionar.
- Tiene capacidad de almacenamiento ilimitada porque se puede montar sobre entornos distribuidos (Spark, Databricks) o en entornos cloud (Azure, AWS, GCP).
- La capacidad de manejar datos no estructurados.
Sin embargo, data lake también plantea otros problemas.
- Tecnológicamente es más complejo de construir.
- Se enfoca más en cargar los datos y no en el consumo que es donde está el valor real.
- Muchas veces se convierte en un repositorio de basura y no de información ya que esta última necesita estar estructurada para poder ser consumida.
- Aumenta la complejidad y cae la performance, lo cual impacta en la productividad porque los equipos trabajan cada vez más aislados.
Las capas de una arquitectura de datos moderna
Las arquitecturas de datos modernas surgen como una respuesta a las dificultades que plantea el data warehouse tradicional. Se componen de tres capas por las que pasan los datos según las transformaciones que se les hagan o según el objeto de su análisis.
Los nombres de estas capas pueden variar según la bibliografía, en este artículo vamos a tomar el enfoque propuesto por la Arquitectura Medallion.
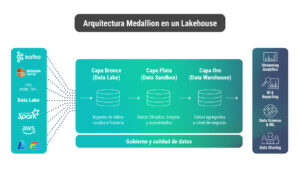
Fuente: Databricks
- Capa 1 – Data lake (Bronce): En ella se encuentran los datos crudos como vienen desde el origen (estructurados o no estructurados) y se almacenan tal cual llegan ya sea que tengan errores, estén duplicados, etc.
- Capa 2 – Data Sandbox (Plata): En este nivel, a los datos ya se les aplicaron ciertas transformaciones y se puede acceder a ellos fácilmente a través de SQL. Aquí trabajan los equipos de ingeniería de datos en las transformaciones, los de ciencia de datos en sus modelos y también podrían ingresar algunos analistas de negocio o power users.
- Capa 3 – Data warehouse (Oro): En este nivel, los datos ya están listos para ser utilizados. La capa de oro posee la mismas características que un data warehouse tradicional, aunque —debido a las otras dos capas que le agregamos— ya no pierde información. A esta capa acceden las personas usuarias finales que por lo general representan el 90% de la comunidad.
Entonces, una arquitectura de datos moderna combina el data warehouse complementado con el data lake.
Recomendaciones para tener en cuenta
Dar forma a una arquitectura de datos moderna implica construir una red de servicios y asignar un propósito específico a cada uno. Antes, el data warehouse resolvía todo, pero ahora hay que pensar, como mínimo, en las tres capas que explicamos más arriba.
Estamos ante un cambió el paradigma: antes modelábamos, cargábamos y analizábamos. Ahora las cosas se hacen al revés: cargamos todo en el data lake, analizamos y, recién ahí, hacemos el modelo.
Pasamos del ETL (extraer, transformar, cargar) al LTE (cargar, transformar, extraer): la estrategia de carga de datos se adapta al volumen y a la capacidad de cómputo. Es decir, en lugar de llevar el dato al cómputo, llevamos el cómputo al dato.
Construir una arquitectura de datos no es algo sencillo. Por lo tanto, hay que hacer todo lo posible para minimizar la complejidad de la solución. Pensemos que después, hagamos lo que hagamos, vamos a tener que mantener la solución. Por eso, la clave es hacer todo de la manera más sencilla posible.



