



For some years now, distributed systems have become a standard for those of us working with data. In this article, we explain, in a very simple way, what they are, how they have evolved, how they work, and how to determine which one we need.
What are distributed systems?
Distributed systems are a set of computers or servers that work in a coordinated manner as if they were one. We can think of them as an orchestra in which different instruments play harmoniously as a whole.
In data & analytics, working with distributed systems has become a standard today because it is the only way we have to scale and store almost infinite volumes of data in a cost-effective manner.
Some of the technologies currently using distributed processing include: Databricks, Spark, Hadoop, Cloudera, Presto, among others.
How did distributed systems evolve?
Over time, the technologies we use in data & analytics have evolved from those with a general purpose (when we used the same tool for everything) to purpose-specific tools (one tool for each task). That’s why we no longer talk about individual tools but directly refer to technological stacks.
To simplify the complexity associated with processing large volumes of data and to meet the data needs of business users, who increasingly demand more information), we had to rethink not only the way we work but also the tools.
Distributed systems emerged as a solution to the two main problems generated by the data warehouse: the need to store more (and more detailed) information along with the slow reaction time (both explained in detail in this article).
Although distributed systems date back to the 1960s, it was in 2009 that the Spark project emerged with the goal of addressing the limitations in data storage capacity and computing power, which were both highly restricted until that moment.
How does a distributed system work?
Any distributed system is a set of components that enable the storage, processing, and management of resources. They are said to have virtually infinite storage and processing capacity because new servers can be constantly added.
There are two ways to scale:
- Vertical: In the case that a server needs more capacity, additional memory or processors can be added, or the server can be replaced with a more powerful one.
- Horizontal: In this case, new clusters (sets of smaller servers) are created. Servers are added side by side to work in a coordinated manner as if they were a single machine.

Traditional Computing vs. Distributed Computing.
Let’s look at this through an example: In our company, we have only one large server, and if it fails, we are left with nothing until it’s repaired or replaced. To avoid this, we decide to have two servers, one as the “primary” and the other as the “backup.” Initially, this would protect us against potential failures. However, having such a large server sitting idle would be a capital waste. To address this, both servers can be put to work, and in the event of a failure, the other one is available. This makes sense.
But what happens if the business starts to scale, and the two servers are no longer sufficient? Eventually, we’ll have to purchase a third server or replace one of the existing ones with a more powerful one. It’s important to note that every time we make any kind of move with one or more servers, there are associated costs.
At this point, distributed systems emerge as a solution. Imagine that, instead of having a single powerful server, we have many smaller servers. If something were to fail, we might not even notice because the loss of capacity would be marginal. Additionally, each of these servers has a much lower cost. They are more standard equipment, which reduces costs by eliminating the need to invest large sums in such massive servers.
Distributed systems propose working through clusters, which are sets of servers that can be used for various purposes. This scheme allows:
- Having high fault tolerance.
- Gaining scalability, as servers can be added or removed as needed.
- Reducing costs.
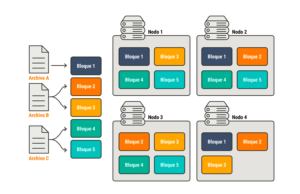
Example of processing in a distributed system with Hadoop.
If we have, for example, three files to store, the distributed system divides them and sends each to a block. These blocks are then distributed across different nodes. Each block becomes part of several nodes, so if a node is lost, we don’t lose information, and that’s the most interesting aspect of this storage method.
This way, read times are much faster, and the system is more efficient. However, not everything is as simple, as managing and configuring such clusters is complex.
The cloud helps address this complexity by offering software as a service (SaaS). In this way, the configuration complexity is not our problem but rather the concern of the cloud service provider we use (Microsoft, AWS, Google, etc.). We simply need to provide instructions: what type of cluster we need, the number of nodes, when it should operate, the storage, etc. With just a few clicks, we’ll have the cluster ready to go, and all we need to do is start loading it with data.
How to determine what type of distributed system I need?
Today, there are many types of distributed systems. When evaluating which one is most appropriate for the company, there is no single answer, as it will depend on the type of organization, the main purpose, data volumes, demand peaks, etc.
- When beginning to consider this, we recommend answering the following questions:
- What is the volume of data I have?
- What is the available budget?
- How do we plan to scale?
- What will the environments be like?
- What are the demand peaks?
- What is the minimum and maximum I need?
- Are there restrictions on processing time?
- What are the periods of low demand?
Defining all this at the outset is crucial. Keep in mind that, afterward, all of this will need to be managed. Regardless of the company’s size, anyone can now access processing capacity that was previously reserved for very few. In the past, significant investments were necessary, but today, all we need is a credit card, the ability to configure the cluster, and—most challenging—the talent and business vision needed to develop such projects.
—
The original version of this article was written in Spanish and translated into English by ChatGPT.



