



In this article, we explain what Databricks is and how it works. We also review the five features that you need to know to use this technology and explain why it is important.
Data in the Digital Era
For some years now, working with data has gone from being important to being critical in organizations. Previously, if a model or a report failed, it did not affect the core of the company. However, today data models are increasingly present in business, so a failure in a data pipeline can have a direct impact on profitability or even prevent part of the organization from operating.
This widespread use of data within companies generates a need for adoption or literacy, which has given much more visibility to internal data analytics areas.
Therefore, the explosion in data demand from the business side has resulted in the need to use new tools and technologies that allow all the information to be processed in a more user-friendly way.
What is Databricks?
Databricks is a platform for working with data that utilizes a form of distributed processing. It is open-source, operates only in the cloud (PaaS), and works in multicloud environments.
In recent years, it has become the ideal solution for those working with data because its functionality significantly simplifies daily tasks. Additionally, it allows engineering, data science, and architecture teams to focus on the important task of extracting value from data processing.
The company was founded in 2013 by the creators of the Spark project (Ali Ghodsi, Ion Stoica, Reynold Xin, and Matei Zaharia). Therefore, we could say that Databricks is a kind of Spark distribution since the tool plays a significant role in its operation.

Ali Ghodsi at the 2023 Databricks Data + AI Summit
Databricks drastically simplifies the tasks of those working in the fields of data and artificial intelligence. How does it achieve this? By integrating all data needs into a single solution. Instead of deploying multiple services to address various needs such as data engineering, data science, artificial intelligence, machine learning, traditional business intelligence, data governance, streaming, and others, Databricks consolidates all these tasks into one place.
How Does Databricks Work?
Databricks operates using the concept of distributed processing, which involves a set of machines working together as if they were a single entity. We can imagine it as an orchestra where each machine is an instrument contributing to the harmony of the whole.
Distributed systems are not new; in fact, they date back to the 1960s. However, it was in 2009 that the Spark project emerged with the goal of overcoming the limitations in data storage and processing capacity that existed up to that point.
In the field of data and analytics, working with distributed systems has become a standard. Why? Because it is the only effective way to scale and process massive volumes of data cost-effectively. It is the answer to the need to handle large amounts of information quickly and efficiently.
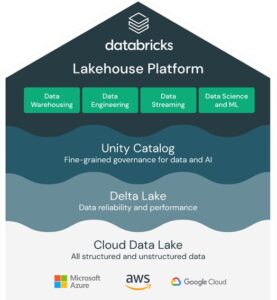
Databricks – Lakehouse Platform
Features to Know to Get Started with Databricks
The five main features that those starting to explore this tool need to know are:
- Databricks is a platform that uses Spark (open source) as its processing engine.
- Databricks is only offered as a cloud service.
- You can practice for free.
- Databricks is for any data profile.
- It is also for business users.
In this article: Databricks: 5 Features to Know to Get Started with This Technology, we develop each of these points.
Why is Databricks Important?
Databricks is transitioning from being aspirational to being the chosen tool for working with data, and the numbers prove it, as at the beginning of 2024, the market value of the company was 43 billion dollars.
Beyond this, the interesting thing is that:
- The same team that designed Spark and founded the company is still doing the same thing ten years later: managing it and being involved in the open-source data world.
- Spark was donated to the Apache Foundation (i.e., it was released as open-source software) and became Apache Spark (a platform we love working with).
- They created Delta Lake, a file type that evolves the functionalities of ORC or Parquet and released it to the Linux Foundation.
- They also developed MLFlow, probably the most widely used tool today for managing the complete lifecycle of Machine Learning/AI models (MLOps). It is also open-source.
- They created Delta Sharing, a protocol to facilitate data sharing, avoiding redundant copies or file exchanges as we did in the past. This too was released to the Linux Foundation.
- And also Dolly and, more recently, DBRX. Large Language Model (LLM) models that are 100% open-source and commercially licensed.
Conclusion
Databricks simplifies the difficult task of configuring and managing a Spark cluster. This is no small feat as in Databricks, the cluster is created with just a few clicks.
In the article: How to Use Databricks? we explain with a video tutorial how to use the tool.
Databricks is for all profiles of people working with data. It allows working via notebooks using SQL, Python, or R (the three de facto languages for data work today). In other words, anyone who knows SQL, R, or Python can work with Databricks and take advantage of all the computing power it has behind it. It is also for business users because, since Spark allows it, any data visualization tool (Power BI, Tableau, MicroStrategy) can be connected to it.
Basically, Databricks allows those working with data to avoid spending time on operational issues (such as cluster maintenance, libraries, etc.) so they can focus on extracting business value from the data, and this is undoubtedly something that is here to stay.
—
The original version of this article was written in Spanish and translated into English by ChatGPT.



