



En este artículo explicamos cómo construir una arquitectura de datos moderna con AWS. Además, describimos cómo es el ecosistema de servicios que ofrece para los proyectos de Data Analytics. Los abordamos desde cada una de las etapas: almacenamiento, ingesta, transformación, explotación y visualización de datos.
¿Cómo construir arquitecturas de datos modernas con AWS?
Una arquitectura de datos provee la información que el negocio necesita para tomar decisiones data-driven. Dar forma a este tipo de arquitecturas implica construir una red de servicios y asignar un propósito específico a cada uno.
Al momento de construir cualquier solución de datos, es importante definir dos cuestiones:
1°) Con qué datos vamos a trabajar: Hay que tener en claro qué datos tenemos disponibles y analizarlos desde tres aristas:
- Estructura del dato: si son estructurados (como por ejemplo las tablas en bases de datos relacionales), semiestructurados (aquellos que tienen una estructura flexible, como los archivos JSON o XML) o no estructurados (videos, imágenes, comentarios en redes sociales, etc.)
- Frecuencia de acceso: definir qué tan seguido accederemos a los datos. Tengamos en cuenta que, a mayor frecuencia, mayor costo y viceversa.
- Volumen de datos: este punto tiene que ver con la cantidad. Recordemos que, a más volumen, mayor latencia y viceversa.
2°) Quién y cómo usará los datos: Esto apunta al perfil de la persona usuaria de los datos. Podrían ser equipos de ciencia de datos, de arquitectura, de ingeniería, de visualización, Data Product Managers, Business Sponsors, áreas de gobierno, etc. Hay que anticipar esto al momento de pensar la solución ya que todos tienen un nivel de conocimiento diferente en cuanto al uso de los datos.
Una vez que estas cuestiones queden definidas, será el momento de elegir el servicio de AWS que mejor se adapte a esas características.
¿Cómo es el ecosistema de servicios de AWS?
AWS es un proveedor de nube que permite elegir servicios puntuales para resolver necesidades de negocio específicas.
Hablamos de ecosistema de servicios porque cada uno de ellos se puede conectar a otros a partir de las necesidades de negocio. Los servicios se agrupan a partir de la función que cumplen en cada momento del proceso de data analytics:
- Almacenamiento.
- Ingesta.
- Transformación.
- Explotación.
- Seguridad.
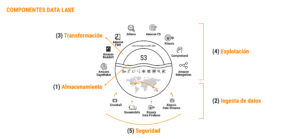
Componentes de un data lake
En la siguiente imagen se puede ver un mapa del ecosistema de servicios de data analytics que ofrece AWS.
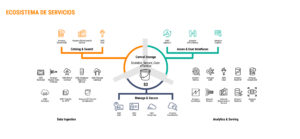
Ecosistema de servicios – Fuente: AWS
¿Cuáles son los servicios de almacenamiento de datos en AWS?
Empecemos por el principio: dónde y cómo almacenar los datos. S3 (Simple Storage Service) es el servicio de almacenamiento en el data lake, sus principales características son:
- Es durable: los datos que almacenemos en este espacio, no los vamos a perder. La probabilidad que esto suceda es realmente muy baja.
- Disponibilidad: Está diseñado para ofrecer el 99.99% de disponibilidad, lo que hace que los datos estén al alcance de la mano.
- Es fácil de usar: tiene APIs simples y es sencillo de configurar.
- Es escalable: podemos almacenar todo tipo de archivos y escalar almacenamiento y capacidad de cómputo de forma independiente, a un límite prácticamente infinito.
- Integración con otros servicios de AWS: Se integra fácil con los demás servicios.
❗Como ya explicamos en otros artículos, el data lake solo tiene valor por el uso que le damos. El objetivo no puede ser solamente almacenar los datos —y correr el riego de transformarlo en un data swamp—, tenemos que lograr que el negocio los use para fines específicos.
💻 A modo de ejemplo, en este video mostramos cómo es la consola de AWS y cómo configurar buckets en S3.
¿Cuáles son los servicios de ingesta de datos en AWS?
Una vez configurado S3, llegó el momento de empezar a llenarlo. En esta etapa hay que definir qué tipo de ingesta haremos, para eso hay que tener en cuenta los siguientes aspectos:
- Origen de los datos: los tres orígenes más comunes son archivos, bases de datos y stream. Hay que considerar esto ya que no es lo mismo ingestar un archivo plano que un stream.
- Frecuencia de actualización: las opciones que podemos elegir son tiempo real, batch, micro batch (por lotes) o diario.
- Volumen: está asociado al origen de los datos. El tamaño puede ser TB, MB o GB.
- Tipo de carga: pueden ser históricas o incrementales.
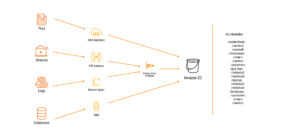
Servicios de ingesta en AWS
Servicios para ingestar bases de datos
AWS ofrece los siguientes:
Amazon Database Migration Service (AWS DMS): Este servicio migra y/o replica, de forma segura, desde diferentes fuentes (bases de datos, data warehouses, bases de datos NoSQL) hacia la nube de AWS. Nació con el objetivo de llevar bases de datos on premise a la nube. Sin embargo, a medida que se masificó la idea del data lake, AWS ofreció la posibilidad de llevar los datos a S3 en paralelo a la migración a la nube. Por lo tanto, lo que hacemos es migrar de la base de datos a S3.
AWS Schema Conversion Tool (AWS SCT): Convierte los esquemas de bases de datos y los data warehouses comerciales a motores open source o a servicios nativos de AWS, como Amazon Aurora y Redshift.
Servicios para ingestar archivos
Hay varios servicios disponibles que dependerán del tipo de sincronización que hagamos y qué tipo de archivos ingestemos. Los más importantes para esta etapa son:
AWS DataSync que sincroniza una unidad de red on premise con S3.
AWS Trasnfer – SFTP.
AWS Snowball/Snowmobile: Estos servicios se usan cuando hay que migrar TB de datos. Son dispositivos que AWS nos entrega, conectamos a nuestra red, descargamos los archivos y AWS los lleva a su rag y guarda todo nuestro bucket.
En esta etapa, para optimizar las transferencias en la nube podemos usar: S3 multi-part upload, S3 transfer acceleration y AWS Direct Connect.
Servicios para ingestar datos en tiempo real
El servicio que se utiliza es Amazon Kinesis que tiene tres variables:
Data Streams: Los datos se capturan por medio de Data Streams, desde allí habrá múltiples consumidores que podrán leerlos. Este servicio captura datos por streaming para procesarlos posteriormente. Una de sus ventajas es que permite crer alertas en tiempo real.
Firehose: Funciona como una especie de plug & play, es menos flexible pero más fácil de usar. Permite enviar datos, pero hace un almacenamiento temporal. Es decir, almacena en un buffer los registros de un stream para escribirlos en una única salida para lograr un almacenamiento más eficiente, algo que no se puede hacer con Data Streams.
Analytics: Complementa a los dos anteriores. Este servicio, mediante SQL, nos permite crear ventanas de tiempo sobre Streams.
💻 A modo de ejemplo, en este video mostramos cómo cómo configurar Kinesis desde la consola de AWS.
¿Cuáles son los servicios de transformación de datos de AWS?
Una vez que elegimos el almacenamiento e ingestamos los datos, llega el momento de empezar a trabajar en las transformaciones. En esta etapa, los servicios que podemos usar son Amazon Glue y Amazon Lambda.
Amazon Glue es la solución por excelencia que AWS ofrece para los procesos ETL (o ELT en data lake). Se trata de un servicio serverless que tiene tres características principales:
- AWS Glue Data Catalog: Es el lugar donde guardamos metadata.
- Glue ETL: Es la característica que nos permite, mediante jobs, hacer transformaciones sobre los datos con código Python o PySpark.
- Crawlers: Una vez que almacenamos algo en S3, el crawler se encarga de mantener actualizada la metadata en el AWS Glue Data Catalog. Luego del proceso de ingesta, rastrea los directorios en S3, hace inferencia de esa información y actualiza el catálogo de metadata.
En cuanto a los procesos de ETL, Glue permite autogenerar código por medio de la generación visual de código (Glue Studio) en lenguajes abiertos como Python/Scala y Apache Spark. Una vez que ya tenemos el script, Glue nos va a permitir ejecutarlo y monitorear o programar esa ejecución. Por último, este servicio también nos permite hacer un workflow, es decir hacer que cada script o job que generemos, después formen parte de algo más grande y orquestado.
💻 A modo de ejemplo, en este video mostramos cómo usar AWS Glue desde la consola de AWS.
Amazon Lambda es un servicio de alcance muy amplio que no necesariamente apunta a analytics.
Para que funcione tenemos que definir una función en algún lenguaje de programación que se va a disparar en base a un evento de origen (como un cambio de estado en una base de datos, llamadas a una API o cambios en el estado de un recurso).
Es serverles y muy flexible, esto permite resolver prácticamente cualquier caso de uso que tengamos.
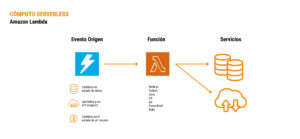
Cómo funciona Amazon Lambda
¿Cuáles son los servicios de explotación de datos de AWS?
Después de haber hecho todo lo anterior, llegó el momento de empezar a analizar los datos. Para esto AWS ofrece dos servicios principales:
Amazon Athena: Este servicio permite ejecutar consultas interactivas simplificando el análisis de datos directamente desde S3, es decir, desde el data lake gracias al AWS Glue Data Catalog. Es serverless, costo efectivo (pago por uso, cuesta USD 5 por TB) y cualquier persona que trabaje con SQL puede usarlo (ANSI SQL).
💻 A modo de ejemplo, en este video mostramos cómo usar Amazon Athena desde la consola de AWS.
Amazon Redshift: Es el servicio de AWS que se ocupa del data warehouse. En esta etapa es importante asegurar la calidad de los datos. Es una tecnología que trabaja en forma paralela (MPP) y ANSI SQL. Si bien no es serverless, es completamente administrado por AWS. Tiene una escalabilidad garantizada y se integra con el data lake.
¿Cuáles son los servicios de visualización de datos de AWS?
Amazon QuikSight es una herramienta de BI tradicional que permite generar gráficos, mapas, etc. Lo interesante es que es serverless, customizable y embebible (los tableros que generamos después se pueden integrar en una plataforma propia).
Este servicio tiene algunas características de machine learning como ser narrativas automáticas, predicciones, detección de anomalías y machine learning.
SageMaker: Es un conjunto de servicios para el trabajo con machine learning e IA. Nos facilita todas las etapas de un proyecto de este tipo, como la preparación de datos, la elección de modelos, la parametrización y la implementación.
Conclusiones
Las arquitecturas de datos moderas se construyen como una red de servicios, ya no son estructuras monolíticas. Hay que considerarlas como una solución de data analytics compuesta por distintos componentes de propósito específico.
Tenemos que cambiar el paradigma tradicional, antes modelábamos los datos, después los cargábamos y después los analizábamos, esta secuencia es propia del data warehouse tradicional. Hoy, al trabajar con data lakes, el orden cambió: lo que hacemos es cargar, analizar lo necesario y modelar lo que tenga sentido (de ETL a ELT).
Es fundamental trabajar en un buen Gobierno de Datos: con fuentes diversas, servicios de propósito específico y tantos productos derivados de los datos, tener un buen gobierno es más importante que nunca.
Hagamos las cosas simples, esto es fundamental al momento de trabajar con este tipo de arquitecturas. Minimicemos la complejidad, incrementémosla según corresponda, prioricemos la flexibilidad y el mantenimiento.
Es fundamental diseñar para el largo plazo pero implementar en el corto. Tenemos que identificar necesidades de negocio concretas que existan hoy pero que estén en línea con el diseño a largo plazo. Buscamos eso para entregar valor a los usuarios y para probar de forma real el diseño a largo plazo de nuestras arquitecturas.



