



En este artículo explicamos cuáles son las 5 características que hay que conocer para empezar con Databricks. También profundizamos en qué es y cómo funciona Databricks, qué son las arquitecturas lakehouse y qué tipo de problemas vienen a resolver. Para terminar, explicamos cómo usar Databricks Community, la versión gratuita para empezar a probar la plataforma.
¿Qué es y cómo funciona Databricks?
Databricks es una herramienta que simplifica notablemente las tareas de quienes trabajamos en data & AI porque integra todas las necesidades de datos en una única solución. En vez de implementar un servicio para cada necesidad (ingeniería, ciencia de datos, inteligencia artificial, machine learning, business intelligence tradicional, gobierno de datos, streaming, etc.) Databricks consolida todo el trabajo en un solo lugar.
Para funcionar utiliza procesamiento distribuido, un conjunto de máquinas que trabaja de forma coordinada como si fuera una sola. Podríamos pensarlas como si fueran una orquesta en la cual hay diferentes instrumentos que suenan de forma armónica como un todo.
Los sistemas distribuidos datan de los años sesenta, sin embargo fue en 2009 que surgió el proyecto Spark con el objetivo de resolver el problema de la capacidad de almacenamiento de datos y la capacidad de cómputo, ambas muy restringidas hasta el momento.
En data & analytics hoy es un estándar trabajar con sistemas distribuidos porque es la única forma que tenemos de escalar y de procesar volúmenes infinitos de datos a una forma costo-efectiva.
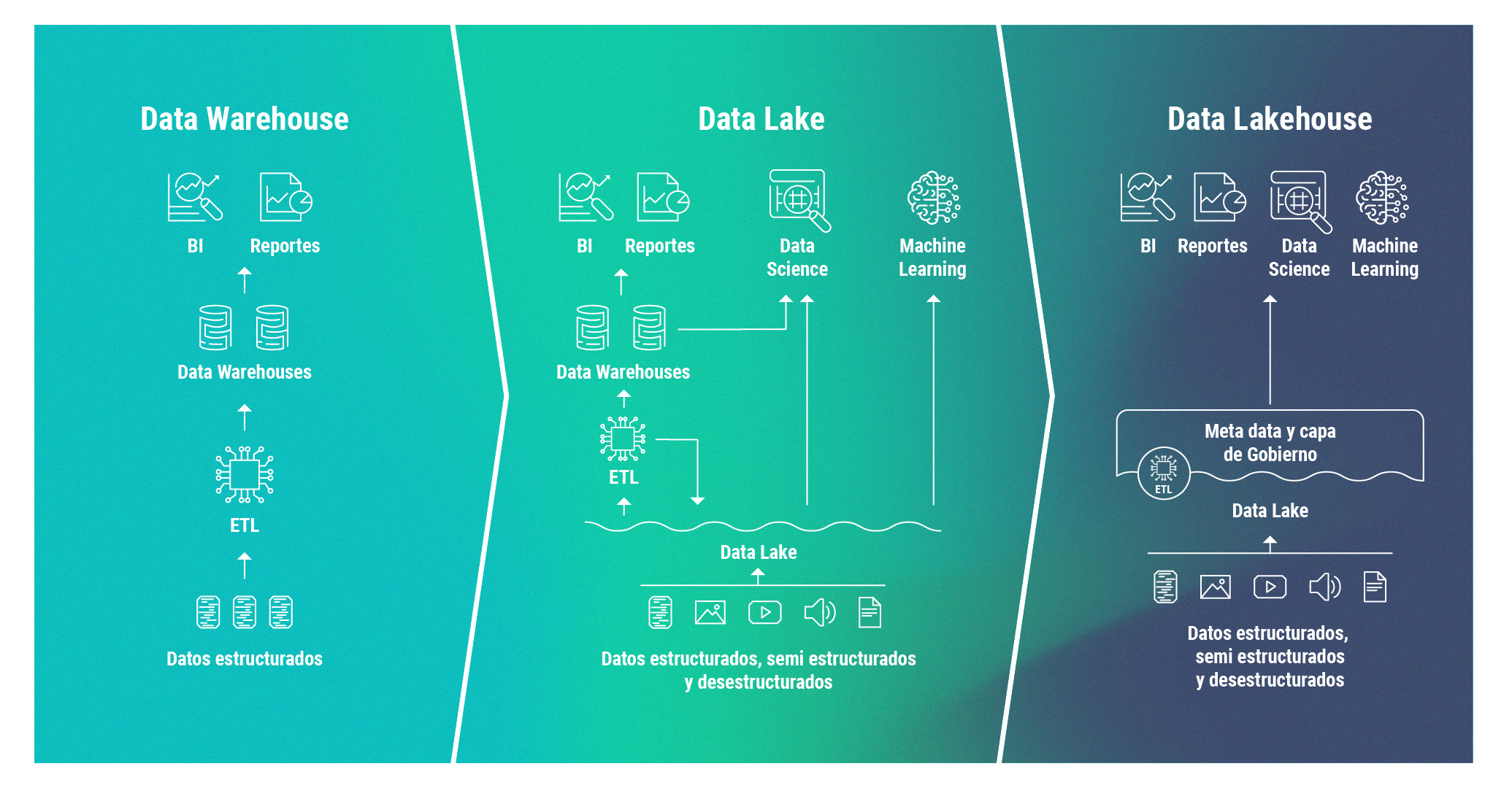
Lakehouse: ¿qué es y qué vino a resolver?
La arquitectura lakehouse es la evolución del data lake (entendido como un repositorio de datos crudos). A diferencia de este último, el lakehouse es un paradigma que incorpora tecnologías que le dan capacidades de comportarse como una base de datos (transacciones, updates, etc.) y garantizan mejoras en los tiempos de respuestas al realizar consultas SQL.
Lakehouse es un concepto que introduce Databricks y busca resolver los problemas que históricamente tuvieron el data lake y el data warehouse. La arquitectura lakehouse combina la estrategia de almacenamiento costo-efectiva y la flexibilidad del data lake con la performance y la disponibilidad de datos de calidad del data warehouse.
Los datos se centralizan en el lakehouse y se usan directamente desde allí. Cualquiera sea el objetivo, no importa si se trata de ciencia de datos, de marketing o de ingeniería, esta arquitectura propone cubrir las necesidades de datos de todas las personas que los requieran.
Sus principales ventajas son:
- Elimina la complejidad asociada al uso de múltiples tecnologías.
- Centraliza los datos en el mismo lugar.
- Es escalable, costo-efectivo y flexible.
- Centraliza todas las actividades de datos, no importa el perfil de la persona.
- Soporta transacciones ACID (Atomicity, Consistency, Isolation y Durability).
Esto es posible gracias a que utiliza sistemas distribuidos.
Fuente: Databricks
5 características que hay que conocer para empezar con Databricks
Las cinco principales características que tienen que saber quienes están empezando a explorar esta herramienta son:
1. Databricks es una plataforma que utiliza Spark (open source) como motor de procesamiento.
La empresa fue creada por los fundadores de Spark y esto tiene una gran influencia. Databricks también desarrolló otros proyectos importantes en el ecosistema de datos (como ML Flow o el formato Delta) que son abiertos a la comunidad, por lo tanto, no hay que tener miedo al vendor lock-in.
2. Databricks solo se ofrece como servicio en la nube.
Es una tecnología que no se puede instalar on-premise. Actualmente soporta las principales nubes del mercado (Microsoft Azure, AWS, GCP, etc.) y se puede usar en esquemas multi-cloud.
Crear un cluster en Databricks es muy sencillo, esta característica es importante porque nos ahorra la complejidad asociada a la administración del cluster Spark. Recordemos que, si bien trabajar con sistemas distribuidos está de moda, esto no significa que sea fácil.
Usar plataforma como servicio (PaaS) nos permite aprender y trabajar de una forma sencilla para concentrarnos en lo que aporta real valor (el procesamiento de los datos) y no emplear tiempo en tareas rutinarias como el mantenimiento del cluster.
3. Se puede practicar gratis.
La versión comunitaria de Databricks vino a resolver una de las principales barreras que tenían los sistemas distribuidos: no se podían probar.
En Databricks Community pueden darse de alta y acceder a todo el front-end de Databricks. Lo más interesante es que en este espacio se pueden probar las características principales para comenzar a utilizar la herramienta.
Esta versión está pensada para practicar y para aprender. Al funcionar totalmente en la nube, permite levantar gratis clusters de Databricks que, si bien son chicos —de un solo nodo — nos habilita a probar los diferentes features.
4. Databricks es para cualquier perfil de datos.
No importa si se trata de ingenieros/as, data scientists, analistas de negocio, etc. Databricks es una solución de plataforma como servicio, muchos de sus features se basan en Apache Spark, por lo tanto, permite trabajar vía notebooks usando SQL, Python, R, Scala, etc. los lenguajes que más se utilizan con el trabajo con datos.
Cualquier persona que sepa SQL, puede trabajar con Databricks.
5. También es para personas usuarias de negocio.
Databricks permite conectar cualquier herramienta de visualización (Power BI, Tableau, MicroStrategy). No importa qué perfil tengamos, vamos a poder usar esta plataforma para trabajar. Además, Databricks integra Redash, que permite hacer consultas SQL a diferentes motores de base de datos, lo que hace que desde la herramienta podamos construir nuestros propios tableros.
Para terminar, dejamos algunas conclusiones:
- Databricks elimina la complejidad asociada al uso de varias tecnologías porque centraliza el acceso, la manipulación y la gestión de los datos en el mismo lugar. Es decir, simplifica de sobremanera el stack de herramientas de datos y, en este contexto de diversidad tecnológica, cualquier simplificación es más que bienvenida.
- Databricks permite trabajar tanto de manera batch (procesando los datos por determinados períodos de tiempo) como en streaming (procesamiento en tiempo real).
- Incorpora Delta Live Tables, que básicamente, es un framework que permite construir pipelines de datos confiables, mantenibles y testeables. Esto lo que hace es simplificar la construcción de pipelines en tiempo real y en batch.
- Incorpora Unity, una solución de Gobierno de Datos que permite hacer catálogo de datos, tener un linaje automático y centralizar el manejo de la seguridad en un mismo lugar.
- Inteligencia artificial: Databricks incorpora Dolly que es un Large Language Model (LLM) de código abierto basado en el seguimiento de instrucciones. Además, Dolly 2.0 permite crear y personalizar LLMs potentes sin costos de API ni compartir datos con terceros.
- Databricks es una plataforma que cubre diferentes temas en boga en el mundo de data & AI. Es una herramienta muy amplia que abarca nube, sistemas distribuidos, Spark y procesamiento de datos en general.
- Databricks todavía es un aspiracional para quienes trabajamos con datos. Tiene cierta complejidad, no desde lo tecnológico necesariamente, pero sí desde lo cultural porque, en cierta forma, propone una nueva forma de hacer las cosas.



