



En este artículo desarrollamos en detalle qué es un data lake, cuáles son sus ventajas y sus desventajas. Además, explicamos cómo se componen este tipo de arquitecturas y qué sucede en cada una de sus capas.
Data lake: contexto histórico
A principios del siglo XXI, surgieron nuevos tipos de datos en volúmenes cada vez mayores. Empezamos a ver transacciones comerciales basadas en la web, transmisiones en tiempo real, datos de sensores, de redes sociales y muchos nuevos tipos de datos que tenían un enorme potencial de explotación.
Con esta abundancia disponible, se hizo evidente la necesidad de contar con nuevas arquitecturas de datos modernas que nos permitieran almacenar y analizar grandes cantidades de datos semiestructurados (aquellos que tienen una estructura flexible, como los archivos JSON o XML) y no estructurados (los que no tienen una estructura definida, como videos, imágenes, comentarios en redes sociales, etc.) con el propósito de obtener información que puede aprovecharse para tomar mejores decisiones de negocio.
¿Cuáles son los problemas del data warehouse?
Antes del surgimiento del data lake, las arquitecturas de datos tradicionales, básicamente, se centraban en el concepto de data warehouse (en este artículo explicamos en detalle qué es). Sin embargo, esta arquitectura, a pesar de tener muchas ventajas, también cosechó algunas críticas. Dos de las principales fueron:
- Rigidez: La poca flexibilidad de los modelos de datos complejos y estáticos puede representar una limitación significativa. En un data warehouse el modelo se establece antes de la carga de datos, esto significa que puede tener dificultades para gestionar los datos no estructurados o aquellos que sean propensos a cambios frecuentes.
- Dificultad para el procesamiento de datos en tiempo real: Si bien los data warehouses están diseñados para soportar procesos por lotes, esta característica puede ser menos eficiente en escenarios en los que se requiere un procesamiento ágil y en tiempo real.
Estas críticas marcaron la necesidad de evolucionar los enfoques tradicionales para abordar de manera más efectiva los nuevos desafíos como implementar ciencia de datos, machine learning, inteligencia artificial y todo tipo de tecnología que permitiera aprovechar mucho más esos grandes volúmenes de datos.
Este contexto, dio lugar al surgimiento de un esquema moderno de gestión de datos empresariales conocido como data lake.
¿Qué es un data lake?
Un data lake es un repositorio de almacenamiento centralizado que permite almacenar datos en crudo, no procesados, en su formato original. Incluidos datos no estructurados, semiestructurados o estructurados, a escala.
Un data lake está montado en entornos distribuidos y ayuda a las empresas a tomar mejores decisiones comerciales a través de visualizaciones u otras formas de análisis, como aprendizaje automático y análisis en tiempo real.
La idea del data lake fue mencionada por primera vez en el año 2010 por el CTO de Pentaho, Jame Dixon: “mientras que un data warehouse parece ser una botella de agua limpia y lista para el consumo, entonces un data lake se considera como un lago entero de datos en un estado más natural”.
¿Cómo se almacenan los datos en el data lake?
Un data lake contiene datos en su forma original y sin procesar. En este caso, y a diferencia de lo que sucede en el data warehouse, los datos se guardan sin hacerles ningún tipo de transformación.
Los datos en el data lake pueden variar drásticamente en tamaño y estructura.
Un data lake puede almacenar cantidades muy pequeñas o enormes de datos, según sea necesario. Todas estas características proporcionan flexibilidad y escalabilidad, esto implica que es una arquitectura que se adapta a almacenar todo tipo de datos y que puede crecer fácilmente a medida que aumente el volumen de información.
¿Cuáles son las ventajas del data lake?
La flexibilidad del data lake permite a las organizaciones ajustar su escala según sus necesidades específicas al separar el almacenamiento de la parte computacional. Esta estrategia elimina la necesidad de llevar a cabo transformaciones y preprocesamientos complejos de datos, que suelen ser característicos en los data warehouses.
Tanto el data warehouse como el data lake son repositorios de datos centralizados. Sin embargo, difieren en su capacidad de almacenamiento ya que en un data warehouse puede ser limitada y en su forma de procesamiento.
Además, estas son otras de sus principales ventajas:
- Resuelve dos de los principales problemas que planteó el data warehouse: pérdida de información y lentitud para reaccionar.
- Tiene capacidad de almacenamiento ilimitada porque se puede montar sobre entornos distribuidos (Spark, Databricks) o en entornos cloud (Azure, AWS, GCP).
- La capacidad de manejar datos no estructurados.
- La posibilidad de manipular datos en tiempo real.
De ETL a ELT
Los enfoques de data warehouse siguen el proceso tradicional ETL. En primer lugar, se extraen (E) los datos de las bases de datos operativas. Luego, los datos se procesan, limpian y transforman (T) antes de cargarlos (L) en las estructuras definidas. Están especialmente diseñados para manejar cargas de trabajo intensivas en lectura para análisis. Los data warehouses necesitan definir su esquema de antemano antes de cargar los datos, lo que se considera un enfoque schema-on-write (esquema al escribir).
En cambio, los data lakes cambian el orden de procesamiento de datos. Almacenan los datos en su formato original, sin realizar el preprocesamiento hasta que se requiere por parte de la aplicación o en el momento de la consulta.
Este enfoque desafía las reglas tradicionales de ETL de los data warehouse, promoviendo la idea de ELT (Extract, Load, Transform) como un cambio en el orden de procesamiento de datos.
Los data lakes no tienen un esquema de datos predefinido, transformando los datos en la forma adecuada solo cuando son requeridos y solicitados por la aplicación para la consulta, utilizando metadatos. Este enfoque se denomina schema-on-read (esquema al leer), evitando la costosa pretransformación de datos y realizando las operaciones de transformación solo cuando los datos se leen del data lake.
¿Cuáles son las desventajas del data lake?
Al trabajar con un data lake, también surgen desafíos relacionados con su implementación y con el análisis de datos. Al igual que en el caso del data warehouse, esta arquitectura también recibió críticas. Algunas de las principales son:
- Tecnológicamente es más complejo de construir.
- Se enfoca más en cargar los datos y no en el consumo que es donde está el valor real.
- Muchas veces se convierte en un repositorio de basura y no de información ya que esta última necesita estar estructurada para poder ser consumida.
- Aumenta la complejidad y cae la performance, lo cual impacta en la productividad porque los equipos trabajan cada vez más aislados.
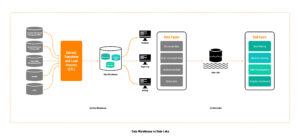
¿Cómo es una arquitectura de datos basada en data lake?
Es importante aclarar que un data lake no reemplaza al data warehouse, sino que lo reversiona, son arquitecturas que se complementan.
Veamos cómo se compone una arquitectura que combina estas capas:
1° Capa data lake: Es donde almacenamos la historia completa. Allí se encuentran los datos crudos, con o sin estructura.
2° Capa sandbox: En esta capa los datos se encuentran parcialmente limpios y es donde los empezamos a transformar.
3° Capa data warehouse tradicional: los datos están estructurados y con la calidad necesaria para su uso por parte de las personas del negocio.

Teniendo en cuenta esta división, este es el proceso de carga de los datos en un data lake:
1° Capa data lake: Una vez definida la forma de consumo de datos (batch, micro batch o tiempo real), por medio de un proceso de ingeniería, vamos a ir a las diferentes fuentes y resguardamos los datos en el data lake. A esta capa solo acceden ingenieros y arquitectos de datos.
2° Capa sandbox: Podemos dividirla en una capa de sandbox analítico (se hacen los modelos exploratorios y los análisis predictivos, ahí trabajan los científicos de datos) y otra de sandbox operativo (donde se hacen las transformaciones en las que trabajan los equipos de ingeniería).
3° Capa data warehouse: Aquí se trabaja con los modelos para tenerlos disponibles en los reportes o en los tableros. Esta capa está lista para que la usen los usuarios de negocio.
Conclusión
El data lake fue diseñado con un fin específico: resolver todas las necesidades de información de la organización. Sin embargo, como explicamos, su implementación es compleja —se necesitan múltiples herramientas para implementarlo lo que supone desafíos para el gobierno de datos— y corremos el riesgo que se transforme en un depósito de basura ya que no se centra en el uso de los datos.
Para resolver esto, es que se crea un nuevo tipo de arquitectura denominada Data Lakehouse.
—
Este artículo fue escrito con los aportes de Rocío Klan.



