



En este artículo explicamos qué es un data lakehouse, qué problemas viene a resolver y cuáles son sus principales características. Además, desarrollamos el concepto de Arquitectura Medallero y profundizamos en cada una de sus capas.
Los problemas del data lake
A medida que los datos empezaron a crecer en formatos, tipos y volumen, el hecho de almacenarlos y procesarlos se volvió un desafío. Para dar respuesta a estos problemas es que en las primeras décadas del siglo XXI surge el concepto de data lake.
Pero, con el tiempo de uso, esta arquitectura también demostró tener algunas falencias. Inicialmente, se creía que bastaba con extraer los datos y depositarlos en el data lake, se lo consideraba como la solución ideal para trabajar con datos estructurados y no estructurados.
Sin embargo, las organizaciones descubrieron que utilizar los datos en el data lake presentaba desafíos diferentes a simplemente almacenarlos allí. En otras palabras: las necesidades de los usuarios finales eran distintas de las de los científicos de datos. Los usuarios finales se enfrentaban a diversos problemas, como conocer la ubicación de los datos, cómo se relacionaban, si estaban actualizados y si eran de calidad.
Las promesas de los data lakes no se cumplieron debido a la falta de soporte para transacciones, al cumplimiento de calidad, a la optimización y al gobierno de los datos.
Esta situación dio origen al término data swamp (pantano de datos). Bill Inmon —científico estadounidense considerado como el padre del — escribió: “en un data swamp, los datos simplemente están ahí y nadie los utiliza. En el data swamp, los datos simplemente se degradan con el tiempo”.
En un proyecto de datos intervienen diferentes perfiles y herramientas: ingenieros de datos, , las herramientas de business intelligence basadas en SQL y las herramientas de machine learning que operan directamente sobre archivos en lenguajes no SQL. De esta manera la implementación de un data lake llevó a una solución dual para abordar todas las necesidades de consumo de datos, es decir, era necesario tener un data lake y un data warehouse.
Esto resultaba en mayores costos en infraestructura, en mantenimiento y en procesamiento, ya que se ejecutaban procesos ELT para llevar datos al data lake y, al momento de llevarlos al data warehouse, el equipo de ingeniería de datos generaba los tradicionales procesos ETL.
¿Qué es un data lakehouse?
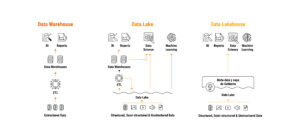
Un data lakehouse es un tipo de arquitectura de datos que combina los beneficios clave del data warehouse y del data lake. De esta manera, proporciona una solución más flexible, rentable y escalable para gestionar y analizar grandes cantidades de datos.
Además, ofrece una mejor gobernanza de datos, un rendimiento mejorado y la capacidad de manejar tanto datos estructurados como no estructurados. Se basa en un almacenamiento de bajo costo y directamente accesible, también proporciona características tradicionales de gestión y rendimiento de sistemas de gestión de bases de datos (DBMS) analíticos.
El concepto de data lakehouse aparece por primera vez en un paper escrito en 2021 por los fundadores de Databricks.
Data Lakehouse – Fuente: Databricks
¿Cuáles son las principales características del data lakehouse?
Estas son algunas de las características más importantes de las arquitecturas lakehouse:
1) Almacenamiento de bajo costo y de acceso directo: Los datos se almacenan en un formato de archivo columnar abierto (como Parquet u ORC) que es de bajo costo y se puede acceder directamente desde una amplia gama de sistemas.
2) Características de gestión y rendimiento de los data warehouses: Utiliza una capa de metadatos para proporcionar características de gestión, como transacciones ACID (atomicidad, consistencia, aislamiento y durabilidad) y versionado de datos.
Esta capa de metadatos se puede implementar a partir de formatos de tabla abiertos como Delta, Iceberg o Hudi. Esta característica es crucial, ya que al separar el almacenamiento del procesamiento y al utilizar formatos abiertos, se elimina la preocupación por el data lock-in. Es decir, se podría cambiar la infraestructura de procesamiento de datos y, con un estándar en un formato abierto, se tendrá acceso directo a los datos sin depender de un proveedor.
Para mejorar el rendimiento de las consultas SQL, también pueden utilizar técnicas de optimización de rendimiento, como el almacenamiento en caché y los índices.
3) Soporte para análisis avanzado: Admiten análisis avanzado utilizando APIs de DataFrame declarativas, que pueden aprovechar las nuevas características de optimización en un lakehouse, como cachés y datos auxiliares, para acelerar aún más el machine learning.
En este artículo explicamos en detalle cuáles son los componentes de las arquitecturas lakehouse.
Los datos contenidos en un data lakehouse se pueden estructurar en una arquitectura de medallero para tener un enfoque único de la verdad.
¿Qué es una arquitectura medallero?
es una manera de organizar los datos en multicapas para categorizarlos en diferentes niveles de calidad o curado de datos.
Está dividida en tres capas. Su nombre es una metáfora de las medallas que se pueden obtener en los juegos olímpicos: bronce, plata, oro. En este caso, cada una de las medallas se asocia a una capa distinta en el data lake.
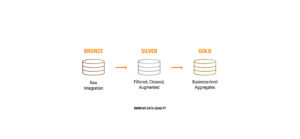
Las capas de la arquitectura medallero
Al igual que en los juegos olímpicos, el color de la medalla indica cierta mejora en cuanto al nivel de las capas: la capa de Plata tendrá datos más refinados que la capa de Bronce y lo mismo con la capa de Oro respecto a la de Plata.
A continuación, explicamos qué datos tendremos en cada capa. Para que se entienda mejor, usamos un ejemplo de información de ventas obtenida de un sistema de gestión de una empresa comercial (como podría ser Salesforce, por citar alguno).
Capa Bronce
En esta capa se almacena la totalidad de los datos crudos tal cual existen en el origen, sin realizar ninguna modificación sobre ellos. Como máximo podríamos llegar a agregar algún campo de referencia sobre la fecha y hora de extracción o que indique el origen del cual obtenemos el dato.
El objetivo de esta capa es tener un único lugar de verdad con toda la información histórica de la organización. Permite acceder de forma fácil a cualquier dato que necesitemos de cualquier origen.
En esta capa pueden existir datos duplicados, con valores incorrectos o vacíos, entre otros problemas. Todo dependerá del nivel de control que realicemos en el origen de los datos.
En el ejemplo que mencionamos, en esta capa se extraerán los datos de Salesforce de los diversos objetos que contiene, como podrían ser las oportunidades, las ventas, los productos, los clientes, etc.
Capa Plata
En la siguiente capa tomamos los datos de la capa de Bronce y realizamos diversas transformaciones y enriquecimientos, esto puede incluir, entre muchas operaciones, las siguientes:
- Eliminación de registros duplicados.
- Corrección de valores erróneos o faltantes.
- Enriquecimiento con datos de diferentes orígenes.
- Transformación de tipos de datos más genéricos a tipos de datos más específicos.
Los datos en esta capa ya se consideran confiables. Ya pasaron por ciertos controles de calidad y pueden ser utilizados para elaborar ciertos indicadores y aplicar las reglas de negocio necesarias para obtener información relevante.
Siguiendo con nuestro ejemplo, en esta capa podríamos filtrar las ventas que incluyan códigos de clientes inexistentes, comparando contra los datos de clientes que también obtuvimos, asignando en todos estos casos un cliente genérico como “Cliente no registrado”. Lo mismo se podría aplicar con las ventas que se reciban con códigos de producto inexistentes, se asigna un código genérico de “Producto inexistente”.
Capa Oro
En esta última capa almacenamos datos ya organizados y/o agregados siguiendo determinadas reglas de negocio. Así podemos alimentar las necesidades de consumo de los diversos usuarios o dar respuesta a una necesidad de visualización para armar un reporte.
Los datos los obtenemos a partir de la capa de Plata. En esta instancia solemos hacer dos operaciones:
- Agregaciones de datos: A partir de datos con un nivel de detalle muy alto (como podrían ser los registros de cada operación realizada), necesitamos realizar agregados por día, por semana o por mes, obteniendo un registro con el acumulado de las operaciones en esos plazos.
- Combinación de diferentes registros: Solemos enriquecer aún más los datos, cruzando las distintas tablas de la capa de Plata y armando una única tabla que cruza las diferentes tablas y selecciona algunos campos relevantes.
En el ejemplo que manejamos de Ventas, en la capa de Oro podríamos agregar los datos y armar dos reportes de:
- Top 10 de productos vendidos en el último mes.
- Monto de ventas diario en los últimos dos meses.
Es en la capa Oro donde ubicaríamos las tablas que antes estaban en el Data Warehouse en formato de modelo estrella o copo de nieve, para que sean consumidos por los distintos clientes de los datos.
Una recomendación adicional para procesar los datos entre las distintas capas es tratar siempre de separar la lógica de procesamiento de cada capa en una o más notebooks.
Aplicar este criterio permite, ante el fallo en el procesamiento, identificar fácilmente en qué etapa del procesamiento ocurrió el fallo. Así podremos analizarlo más rápido y volver a ejecutar desde el punto de falla, sin necesidad de, por ejemplo, reprocesar los datos de Bronce a Plata si el fallo ocurrió cargando los datos en la capa de Oro.
Conclusión
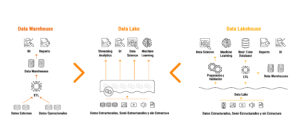
La arquitectura lakehouse propone combinar las características de almacenamiento costo-efectivas propias del data lake con la performance y la disponibilidad de un data warehouse.
Evolución de Plataformas de Datos hacia el nuevo modelo de Lakehouse – Fuente: Databricks.
Las principales ventajas que encontramos en un data lakehouse son:
- Elimina la complejidad de múltiples herramientas asociada a la implementación de un data lake.
- Se centraliza en un único lugar.
- Es escalable.
- Centraliza las actividades de ingenieros de datos y científicos de datos en una única herramienta.
- Permite gestionar la metadata, utilizar versionado. Para hacer esto, utiliza un motor llamado Delta Lake. Se trata de una herramienta que permite aprovechar las ventajas de un data lake y un data warehouse centralizado en un mismo lugar.
En resumen, una arquitectura lakehouse aspira a superar las limitaciones percibidas de las arquitecturas tradicionales de data warehouse y data lake, ofreciendo una solución integrada y eficiente para la gestión de datos analíticos a gran escala.
—
Este artículo fue escrito con los aportes de Rocío Klan y Gabriel Arch.



