



En este artículo explicamos qué son los agentes de IA generativa. Cuáles son las técnicas actualmente disponibles para construirlos: Prompt engineering, Build from scratch, Fine-tuning y Retrieval-Augmented Generation (RAGs). Además, damos una serie de consejos útiles al momento de desarrollarlos.
Agentes de IA generativa: contexto
A finales de 2022, OpenAI dio a conocer ChatGPT, el mayor exponente de la IA generativa hasta el momento. Esta última, es una rama de la IA que genera contenido nuevo a partir de datos que ya existen.
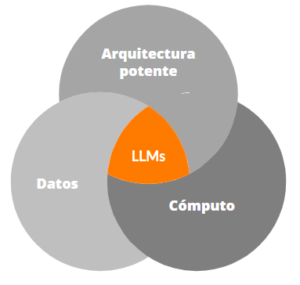
Históricamente, esto se da debido a que estamos en una época en la que se combinan tres factores:
- Arquitecturas potentes: Permiten procesar cadenas de textos, lo que habilita a los algoritmos a entender la dimensión semántica, es decir, el sentido del texto.
- Capacidad de cómputo: Las distintas nubes ofrecen tecnología capaz de procesar de forma accesible lo que antes era muy costoso.
- Datos: Contamos con grandes volúmenes de información curada que es la base para entrenar estos modelos.
¿Qué es un Large Language Model (LLM)?
Un Large Language Model (LLM) es una combinación de algoritmos que generan texto predictivo a partir de una gran cantidad de datos. Estos modelos de lenguaje fueron entrenados con grandes volúmenes de información. La gran diferencia respecto a lo que ya conocíamos es el crecimiento exponencial de sus capacidades: cuando entrenamos un modelo con pocos datos, sus capacidades serán limitadas, en cambio cuando el volumen de datos crece, sus capacidades también lo hacen (y mucho).
¿Qué es un agente de inteligencia artificial generativa?
Un agente de IA generativa es un software que puede interactuar con su entorno, obtener datos y utilizarlos para realizar tareas específicas de forma autónoma para cumplir ciertos objetivos preestablecidos. Si bien las personas definen esas metas, es el agente de IA el que elige las acciones más apropiadas a ejecutar para alcanzarlas.
Estos agentes, surgen como nuevas herramientas que maduraron durante los últimos meses y lo seguirán haciendo.
Uno de los primeros usos que vimos fue ChatGPT (un bot con IA generativa que nos permite conversar), al poco tiempo, vimos que podíamos construir cosas un poco más complejas como chatbots que se alimentarán de datos proporcionados por nosotros para usarlos como fuentes de conocimiento y responder preguntas más específicas.
En este artículo explicamos en detalle qué es la IA generativa y cómo funciona.
El hecho de hablar de “agentes” significa que recibimos asistencia de parte de un tercero que ya no es una persona de carne y hueso sino una solución de IA. Estamos en el momento en el que empezamos a construir este tipo de herramientas.
Técnicas para construir agentes inteligentes
Construir un agente es, básicamente, construir algo que haga algo. Para hacer esto, existen diferentes técnicas, lo más fácil es usar:
Prompt engineering:
Es la forma más sencilla y conocida. Consiste simplemente en hacer buenos prompts y apoyarse en algún modelo existente (como ChatGPT, Bard, etc.) En este caso, los datos que se usan son estáticos y del mundo exterior.
La ventaja de esta técnica es que es muy fácil de poner en práctica ya que demanda muy poco trabajo de nuestro lado. Sin embargo, estos agentes no tendrán información propia de nuestra organización porque son modelos de LLM que fueron entrenados con información disponible en internet que no es propia.
Por lo tanto, si queremos armar un modelo usando nuestros propios datos, habrá que apoyarse en alguna de las opciones que explicamos a continuación.
Build from scratch:
Como la expresión lo indica, consiste en hacer el propio modelo desde cero. La ventaja es que utiliza datos específicos de nuestra realidad. Sin embargo, son estáticos y es costoso construirlo ya que obligan a tener muchísima información. A pesar de esto, hay empresas —como Bloomberg, la empresa de información financiera, por ejemplo— que eligen este camino.
Fine-tuning:
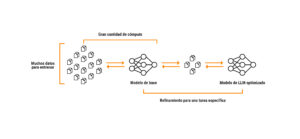
Consiste en usar un modelo ya disponible (como ChatGPT o Bard) y refinarlo con información propia. Para entrenar este tipo de modelos se necesitan grandes cantidades de datos y capacidad de cómputo.
Esta forma de aprendizaje implica partir de un modelo de base y refinarlo para que se comporte distinto. Se recomienda siempre y cuando tengamos suficientes datos (muchos) para enseñarle algo. Puede ser una buena opción si lo necesitamos para algo que no sea demasiado dinámico y que no esté asociado al paso del tiempo, ya que, su principal desventaja es que la información propia que entra al modelo, permanece estática.
Este tipo de agentes no contarán con la última información y actualizarla dentro de un modelo existente es un proceso complejo. Los modelos trabajan por repetición, entonces, si tienen pocos datos de un tema, se van a diluir en los muchos datos que tengan sobre otro tema. Como resultado, el modelo resulta lento, caro —y lo peor— estático ya que no será capaz de aprender cosas nuevas.
Fine-tuning – Proceso de refinado
Retrieval-Augmented Generation (RAGs)
Los Retrieval-Augmented Generation (RAGs) son una forma de aprendizaje que consiste en usar un modelo (refinado o no) y conectarlo a una base de datos propia. De esta manera, es posible conversar con la información que necesitemos de nuestra propia empresa. Es la forma de buscar información relevante y de organizarla para que un LLM pueda usarla para generar una respuesta.
Por todos estos motivos, de todas las que mencionamos anteriormente, esta es la técnica recomendada.
¿Cómo funcionan los Retrieval-Augmented Generation (RAGs)?
Esta técnica es la más recomendable para construir nuestros propios agentes inteligentes. Los RAGs son cada vez más potentes, más estables y el costo es menor.
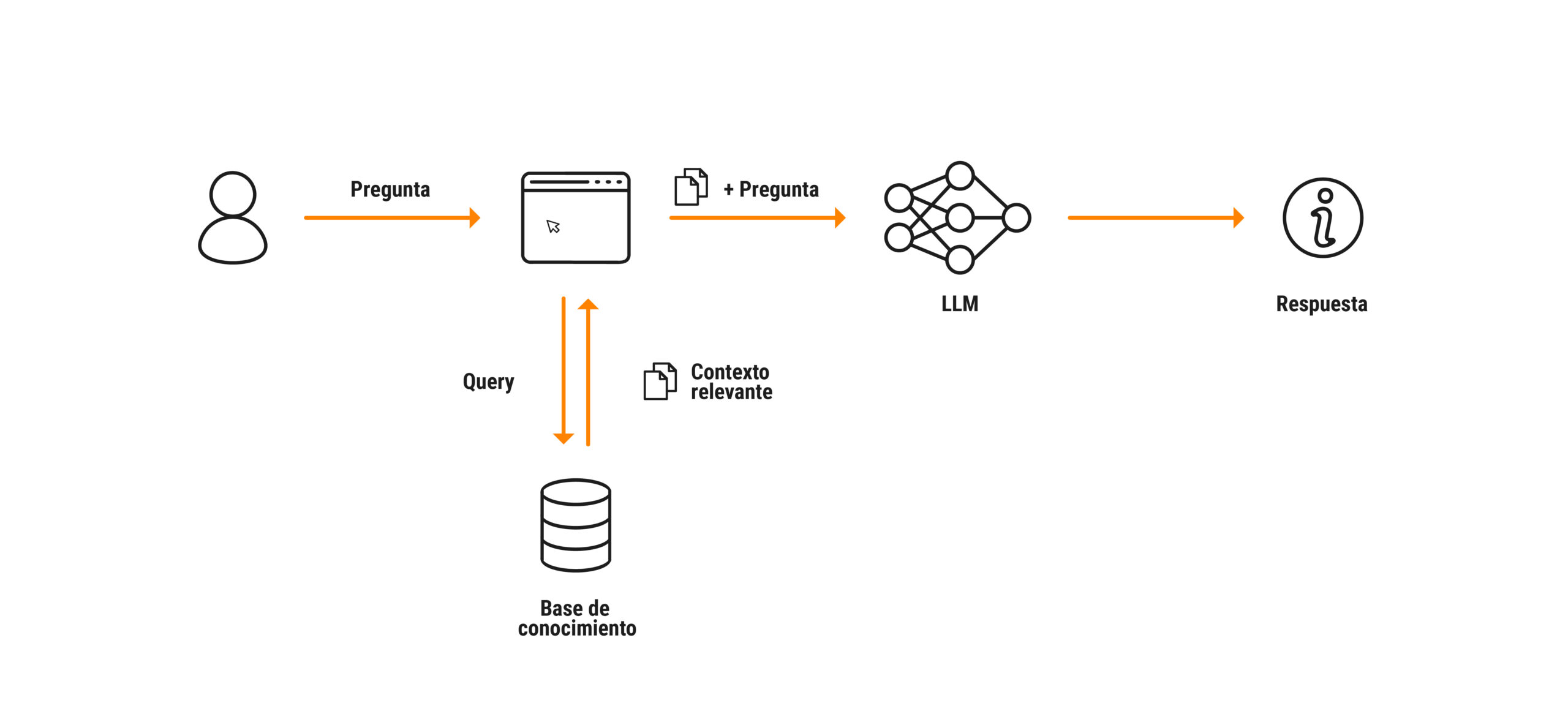
Arquitectura Retrieval-Augmented Generation (RAG)
1° Partimos de una interfaz que recibe la pregunta de la persona. Puede ser, por ejemplo: ¿Cuál es el número de teléfono de servicio al cliente?, ¿cómo es el proceso para pedir vacaciones? o demás interrogantes relacionados con una base de datos propia.
2° Después pasamos a la base de datos propia, es decir, a nuestra realidad para buscar la información necesaria para responder. Estos datos funcionan como el contexto que hará que esa respuesta sea válida. ❗ Estos modelos para dar respuestas acertadas necesitan mucho y muy buen contexto.
3° Después pasamos al modelo LLM. Le damos la pregunta de la persona y le indicamos que busque la respuesta en nuestra base de conocimiento, es decir, en la información específica que definimos como contexto, no en otro lugar.
4° El modelo da la respuesta a la persona basada en la información disponible en nuestra base de conocimiento.
Los RAGs permiten desarrollar agentes inteligentes sin armar un nuevo modelo. Lo usamos tal como está (con la información que tenga, no importa cuál ni de dónde venga) y le agregamos nuestras propias bases de conocimiento. Cuando hacemos la consulta, le pedimos que busque la respuesta a partir de nuestros datos. De esta manera, el agente ya no buscará en todo lo que hay disponible en internet, sino que lo hará en el contexto que le indiquemos.
Los RAGs, no solo son eficientes, también son económicos y livianos de implementar. No es necesario reentrenar nada, solo tenemos que dirigir la pregunta al contexto adecuado. Usamos la tecnología que ya alguien desarrolló (un modelo de LLM) para responder sobre nuestra realidad.
¿Qué tener en cuenta al momento de desarrollar un agente inteligente?
Al momento de desarrollar este tipo de agentes hay que:
⚠️ Tener buenos datos: que estén limpios, actualizados, que sean relevantes para el negocio, que resuelvan dolores de las personas, etc.
⚠️ Y sobre todo, que los datos estén asegurados, evitar exponer información sensible, privada.
A continuación, un video en el que explicamos todo esto en detalle de forma muy simple:
Consejos para desarrollar agentes inteligentes
1- Como ya explicamos, cada una tiene sus ventajas y sus desventajas, por lo tanto, utilizar Fine Tunning o RAGs dependerá de la necesidad. Al momento de elegir una u otra técnica, habrá que evaluar qué se quiere lograr y cuáles son los recursos (computacionales y de conocimiento) disponibles.
2- También es importante no subestimar la tarea de limpiar y preparar la información, si bien es lenguaje natural, es importante definir muy cuidadosamente:
- El Chunck Size (la cantidad de partes en las que se dividirán los datos para su procesamiento).
- El tipo de base vectorial.
- La forma en cómo se construyen los embeddings e índices para la base vectorial.
- Validar si vale la pena agregar procesamientos previos como resumir o extraer palabras o patrones claves.
3- Los prompts todavía son un tema de prueba y error (al menos por ahora) por lo que gran parte de los resultados que se obtengan dependerán de cómo se defina el prompt del modelo.
4- Agentes: si la solución requiere de varios pasos de procesamiento para llegar a la “respuesta final” no es recomendable dejar que un solo agente haga todo el trabajo. Es mejor modularizar las tareas, de esa forma tendremos mucho más control sobre cada etapa y podremos identificar dónde ocurren ciertas fallas.
Conclusión
Estamos ante un escenario que se reconfigura todos los días. Lo positivo de esto es que lo que sea que queramos hacer hoy, vamos a poder hacerlo rápido.
Para este tipo de implementaciones aplicamos agilismo puro: probamos, usamos, iteramos y vemos cómo nos mejora el negocio (o no).
Más allá del momento de ebullición actual, estamos en un cambio de época con disrupción e innovación real. Probablemente, en el futuro cercano recordemos 2023 como un año de quiebre.
Este tipo de proyectos son fáciles de implementar a un costo monetario relativamente bajo, lo cual en nuestra opinión, es un llamado al hacer. ¿Por qué esperar más?



