



In this article, we explain what generative AI agents are. What are the currently available techniques to build them: Prompt engineering, Build from scratch, Fine-tuning, and Retrieval-Augmented Generation (RAGs). Additionally, we provide a series of useful tips when developing them.
Generative AI agents: context
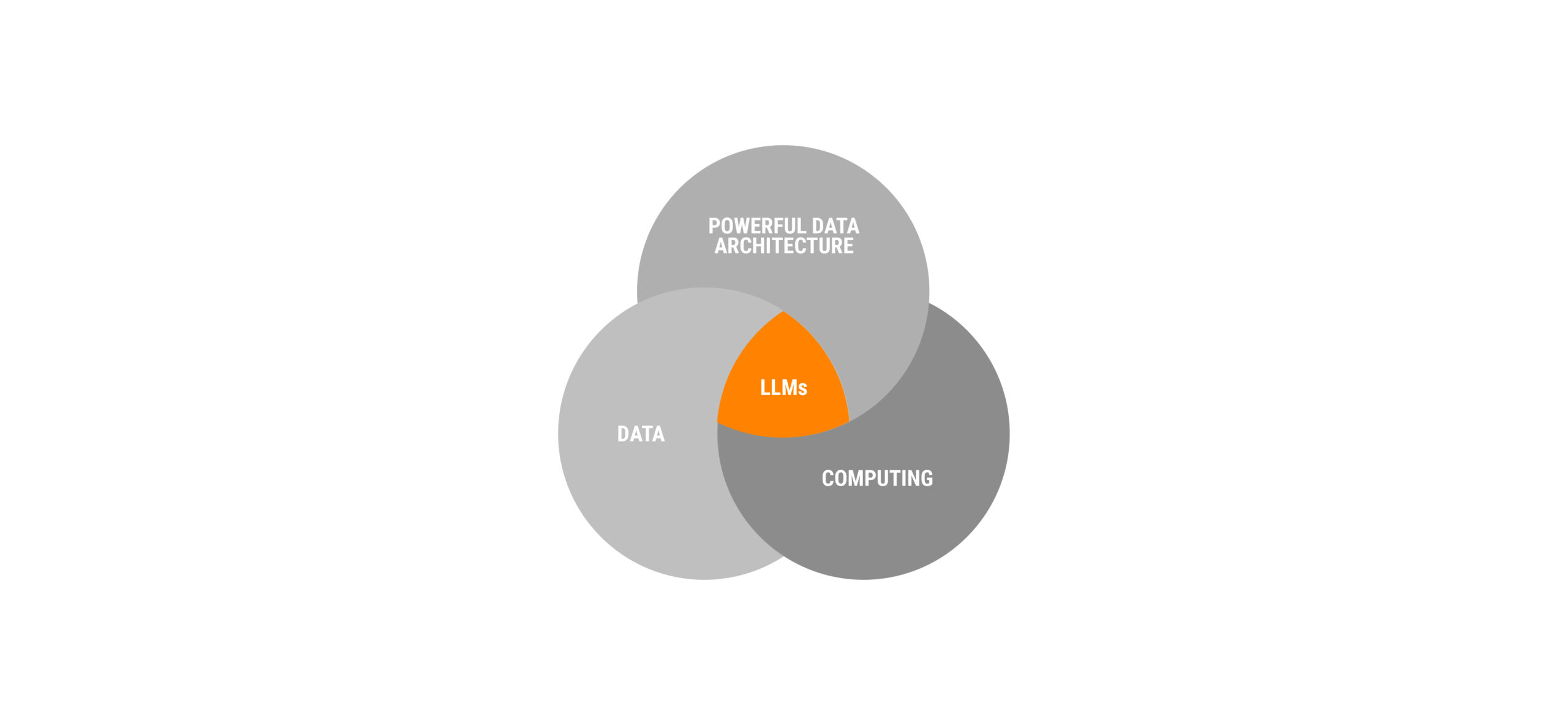
At the end of 2022, OpenAI introduced ChatGPT, the most prominent example of generative AI to date. This is a branch of AI that generates new content from existing data. Historically, this is happening because we are in a time where three factors converge:
1- Powerful architectures: They allow for the processing of text chains, enabling algorithms to understand the semantic dimension, that is, the meaning of the text.
2- Computing capacity: Different clouds offer technology capable of processing in an accessible way what was previously very costly.
3- Data: We have large volumes of curated information that form the basis for training these models.
What is a Large Language Model (LLM)?
A Large Language Model (LLM) is a combination of algorithms that generate predictive text from a large amount of data. These language models were trained with vast volumes of information. The significant difference compared to what we already knew is the exponential growth of their capabilities: when we train a model with few data, its capabilities will be limited, but when the volume of data grows, its capabilities also grow (and significantly).
What is a generative artificial intelligence agent?
A generative AI agent is software that can interact with its environment, obtain data, and use it to perform specific tasks autonomously to meet certain pre-established goals. While people define these goals, it is the AI agent that chooses the most appropriate actions to execute in order to achieve them.
These agents have emerged as new tools that have matured over the past few months and will continue to do so.
One of the first uses we saw was ChatGPT (a generative AI bot that allows us to converse), and shortly after, we saw that we could build slightly more complex things like chatbots that are fed data provided by us to use as knowledge sources and answer more specific questions.
In this article, we explain in detail what generative AI is and how it works.
Talking about “agents” means we are receiving assistance from a third party that is no longer a flesh-and-blood person but an AI solution. We are at the point where we are beginning to build these types of tools.
Techniques for building intelligent agents
Building an agent is, essentially, building something that does something. To do this, there are different techniques, the easiest is to use:
Prompt engineering:
This is the simplest and most well-known way. It simply involves crafting good prompts and relying on an existing model (such as ChatGPT, Bard, etc.). In this case, the data used is static and from the outside world.
The advantage of this technique is that it is very easy to implement as it requires very little work on our part. However, these agents will not have information specific to our organization because they are LLM models trained with publicly available information from the internet, which is not proprietary.
Therefore, if we want to build a model using our own data, we will need to rely on one of the options explained below.
Build from scratch:
As the expression indicates, it involves building the model from scratch. The advantage is that it uses data specific to our reality. However, this data is static, and it is costly to build since it requires a vast amount of information. Despite this, there are companies — like Bloomberg, the financial information company, for example — that choose this path.
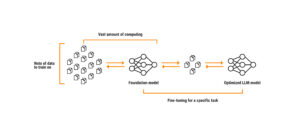
Fine-tuning:
It involves using an already available model (like ChatGPT or Bard) and refining it with proprietary information. Training this type of model requires large amounts of data and computing capacity.
This method of learning involves starting with a base model and refining it to behave differently. It is recommended as long as we have enough data (a lot) to teach it something. It can be a good option if we need it for something that is not too dynamic and not associated with the passage of time, as its main disadvantage is that the proprietary information that enters the model remains static.
These types of agents will not have the latest information, and updating it within an existing model is a complex process. Models work by repetition, so if they have little data on a topic, it will be diluted by the many data they have on another topic. As a result, the model becomes slow, expensive —and worst of all— static, as it will not be able to learn new things.
Fine-tuning
Retrieval-Augmented Generation (RAGs)
Retrieval-Augmented Generation (RAGs) is a form of learning that involves using a model (refined or not) and connecting it to a proprietary database. This way, it is possible to interact with the information we need from our own company. It is the way to search for relevant information and organize it so that an LLM can use it to generate a response.
For all these reasons, of all the techniques mentioned earlier, this is the recommended one.
How do Retrieval-Augmented Generation (RAGs) work?
This technique is the most recommended for building our own intelligent agents. RAGs are increasingly powerful, more stable, and less costly.
Retrieval-Augmented Generation (RAG) Architecture
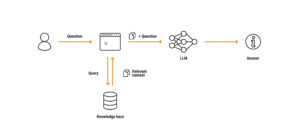
1° We start with an interface that receives the user’s question. For example: What is the customer service phone number? How is the process for requesting vacation? or other questions related to a proprietary database.
2° Next, we consult the proprietary database, i.e., our reality, to find the necessary information to answer. This data serves as the context that makes the response valid.  These models need a lot of good context to provide accurate answers.
These models need a lot of good context to provide accurate answers.
3° Then, we proceed to the LLM model. We give it the user’s question and instruct it to find the answer in our knowledge base, i.e., in the specific information we have defined as context, not elsewhere.
4° The model provides the answer to the user based on the information available in our knowledge base.
RAGs allow us to develop intelligent agents without building a new model. We use it as is (with whatever information it has, regardless of its source) and add our own knowledge bases. When making a query, we ask it to find the answer from our data. Thus, the agent will no longer search through everything available on the internet but will do so within the context we provide.
RAGs are not only efficient but also cost-effective and lightweight to implement. There is no need to retrain anything; we just need to direct the question to the appropriate context. We use technology that someone else has already developed (an LLM model) to respond to our specific reality.
What to consider when developing an intelligent agent?
When developing these types of agents, you should:
 Have good data: it should be clean, updated, relevant to the business, and address people’s pain points, etc.
Have good data: it should be clean, updated, relevant to the business, and address people’s pain points, etc.
And above all, ensure that the data is secured to avoid exposing sensitive or private information.
Here is a video where we explain all this in detail in a very simple way:
Talk: LLMs in Production
Tips for Developing Intelligent Agents
1- As already explained, each technique has its advantages and disadvantages, so whether to use Fine-Tuning or RAGs will depend on the need. When choosing one technique over the other, evaluate what you want to achieve and the resources (computational and knowledge) available.
2- It is also important not to underestimate the task of cleaning and preparing the information. Even though it is natural language, it is crucial to carefully define:
- The Chunk Size (the number of parts into which the data will be divided for processing).
- The type of vector base.
- How embeddings and indices are built for the vector base.
- Whether it is worth adding preprocessing steps like summarizing or extracting key words or patterns.
3- Prompts are still a matter of trial and error (at least for now), so much of the results obtained will depend on how the model’s prompt is defined.
4- Agents: If the solution requires multiple processing steps to reach the “final answer,” it is not advisable to let a single agent do all the work. It is better to modularize the tasks, as this will give you more control over each stage and help identify where certain failures occur.
Conclusion
We are in a scenario that is reconfiguring every day. The positive aspect is that whatever we want to achieve today, we can do it quickly.
For these types of implementations, we apply pure agility: we test, use, iterate, and see how it improves the business (or not).
Beyond the current boiling point, we are in an era of disruption and real innovation. In the near future, we will likely remember 2023 as a breakthrough year.
These types of projects are easy to implement at a relatively low monetary cost, which, in our opinion, is a call to action. Why wait any longer?
—
This article was originally written in Spanish and translated into English with ChatGPT.



