



In this article, we explain what a data lakehouse is, what problems it aims to solve, and what its main characteristics are. Additionally, we develop the concept of the medallion architecture and delve into each of its layers.
The problems of the data lake
As data began to grow in formats, types, and volume, storing and processing it became a challenge. To address these issues, the concept of a data lake emerged in the early decades of the 21st century.
However, over time, this architecture also showed some shortcomings. Initially, it was believed that simply extracting data and depositing it into the data lake was sufficient, as it was considered the ideal solution for working with both structured and unstructured data.
However, organizations discovered that using the data in the data lake presented different challenges beyond just storing it. In other words, the needs of end users were different from those of data scientists. End users faced various problems, such as knowing the location of the data, how it was related, whether it was up-to-date, and whether it was of good quality.
The promises of data lakes were not fulfilled due to the lack of support for transactions, quality compliance, optimization, and data governance.
This situation gave rise to the term data swamp. Bill Inmon —an American scientist considered the father of the data warehouse— wrote: “In a data swamp, the data is simply there, and no one uses it. In the data swamp, the data simply degrades over time.”
In a data project, different profiles and tools are involved: data engineers, data analysts, business users, and data scientists, with business intelligence tools based on SQL and machine learning tools that operate directly on non-SQL language files. Thus, the implementation of a data lake led to a dual solution to address all data consumption needs, meaning it was necessary to have both a data lake and a data warehouse.
This resulted in higher costs for infrastructure, maintenance, and processing, as ELT processes were executed to bring data to the data lake, and when moving it to the data warehouse, the data engineering team generated the traditional ETL processes.
What is a data lakehouse?
A data lakehouse is a type of data architecture that combines the key benefits of both the data warehouse and the data lake. In this way, it provides a more flexible, cost-effective, and scalable solution for managing and analyzing large amounts of data.
Additionally, it offers better data governance, improved performance, and the ability to handle both structured and unstructured data. It is based on low-cost, directly accessible storage and also provides traditional management and performance features of analytical database management systems (DBMS).
The concept of the data lakehouse first appeared in a paper written in 2021 by the founders of Databricks.
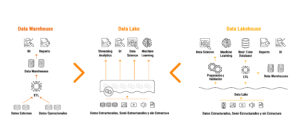
Data Lakehouse – Source: Databricks
What are the main characteristics of a data lakehouse?
Here are some of the most important features of lakehouse architectures:
1) Low-cost, direct-access storage: Data is stored in an open columnar file format (such as Parquet or ORC) that is cost-effective and can be accessed directly from a wide range of systems.
2) Management and performance features of data warehouses: It uses a metadata layer to provide management features, such as ACID transactions (atomicity, consistency, isolation, and durability) and data versioning.
This metadata layer can be implemented using open table formats like Delta, Iceberg, or Hudi. This feature is crucial because separating storage from processing and using open formats eliminates concerns about data lock-in. In other words, it would be possible to change the data processing infrastructure, and with a standard in an open format, direct access to the data would be maintained without relying on a vendor.
To improve the performance of SQL queries, optimization techniques such as caching and indexing can also be utilized.
3) Support for advanced analytics: They support advanced analytics using declarative DataFrame APIs, which can leverage new optimization features in a lakehouse, such as caches and auxiliary data, to further accelerate machine learning.
In this article, we explain in detail the components of lakehouse architectures.
The data contained in a data lakehouse can be structured in a medallion architecture to have a single source of truth.
What is a medallion architecture?
A medallion architecture is a way to organize data in multiple layers to categorize it into different levels of quality or data curation.
It is divided into three layers. Its name is a metaphor for the medals that can be obtained in the Olympic Games: bronze, silver, and gold. In this case, each of the medals is associated with a distinct layer in the data lake.
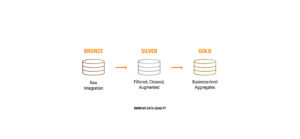
The layers of the medallion architecture
Just like in the Olympic Games, the color of the medal indicates a certain improvement regarding the level of the layers: the Silver layer will have more refined data than the Bronze layer, and the same goes for the Gold layer in relation to the Silver layer.
Next, we explain what data will be present in each layer. To make it clearer, we use an example of sales information obtained from a management system of a commercial company (such as Salesforce, for instance).
Bronze Layer
In this layer, the entirety of the raw data is stored exactly as it exists at the source, without any modifications. At most, we might add some reference fields indicating the date and time of extraction or the origin from which the data is obtained.
The objective of this layer is to have a single source of truth with all the historical information of the organization. It allows easy access to any data we need from any source.
In this layer, there may be duplicate data, incorrect values, or empty fields, among other issues. It all depends on the level of control we exercise at the data source.
In the example mentioned, this layer will extract data from Salesforce from the various objects it contains, such as opportunities, sales, products, customers, etc.
Silver Layer
In the next layer, we take the data from the Bronze layer and perform various transformations and enrichments. This can include, among many operations, the following:
- Removal of duplicate records.
- Correction of incorrect or missing values.
- Enrichment with data from different sources.
- Transformation of more generic data types into more specific data types.
The data in this layer is considered reliable. It has undergone certain quality controls and can be used to develop specific indicators and apply the necessary business rules to obtain relevant information.
Continuing with our example, in this layer, we could filter out sales that include codes for non-existent customers by comparing them against the customer data we also obtained, assigning a generic customer label like “Unregistered Customer” in all these cases. The same approach could be applied to sales that are received with non-existent product codes, assigning a generic code of “Non-existent Product.”
Gold Layer
In this final layer we store data that is already organized and/or aggregated according to specific logics or business rules. In this way, we can meet the consumption needs of various users, such as an external sector or responding to a visualization need for reporting purposes.
We obtain the data from the Silver layer. At this stage, we typically perform two operations:
- Data Aggregations: From data with a very high level of detail (such as records of each transaction performed), we often need to create aggregates by day, week, or month, obtaining a record with the total of transactions over those time periods.
- Combination of Different Records: We further enrich the data by cross-referencing the different tables from the Silver layer and creating a single table that merges the various tables and selects some relevant fields.
In the sales example we’re using, in the Gold layer, we could aggregate the data and create two reports:
– Top 10 best-selling products in the last month.
– Daily sales amount in the last two months.
It is in this final Gold layer where we would place the tables that were previously in the Data Warehouse in star or snowflake model format, so that they can be consumed by various data clients.
An additional recommendation for processing data between the different layers is to always try to separate the processing logic of each layer into one or more notebooks.
Applying this criterion will allow us, in the event of a processing failure, to more easily identify at which stage the failure occurred. This way, we can analyze it more quickly and allow ourselves to re-execute from the point of failure, without needing to reprocess the data from Bronze to Silver if the failure occurred while loading data in the Gold layer.
Conclusion
The lakehouse architecture aims to combine the cost-effective storage characteristics of a data lake with the performance and availability of a data warehouse.
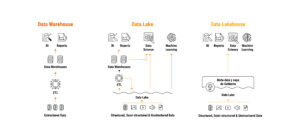
Evolution of Data Platforms towards the new Lakehouse model – Source: Databricks.
The main advantages found in a data lakehouse are:
- Eliminates the complexity of multiple tools associated with the implementation of a data lake.
- Centralizes everything in a single location.
- Is scalable.
- Centralizes the activities of data engineers and data scientists in one tool.
- Allows for managing metadata and using versioning. To do this, it utilizes a engine called Delta Lake. This tool enables leveraging the advantages of both a data lake and a centralized data warehouse in one place.
In summary, a lakehouse architecture aims to overcome the perceived limitations of traditional data warehouse and data lake architectures, providing an integrated and efficient solution for managing large-scale analytical data.
—
This article was originally written in Spanish and translated into English with ChatGPT.



