



Desde hace algunos años, los sistemas distribuidos se convirtieron en un estándar para quienes trabajamos con datos. En este artículo explicamos, de manera muy sencilla, qué son, cómo evolucionaron, cómo funcionan y cómo saber cuál necesitamos.
¿Qué son los sistemas distribuidos?
Los sistemas distribuidos son un conjunto de computadoras o servidores que trabajan de forma coordinada como si fueran una sola. Podríamos pensarlos como si fueran una orquesta en la cual hay diferentes instrumentos que suenan de forma armónica como un todo.
En data & analytics hoy es un estándar trabajar con sistemas distribuidos porque es la única forma que tenemos de escalar y de almacenar volúmenes casi infinitos de datos a una forma costo-efectiva.
Algunas de las tecnologías que utilizan procesamiento distribuido en la actualidad son: Databricks, Spark, Hadoop, Cloudera, Presto, entre otras.
¿Cómo evolucionaron los sistemas distribuidos?
Con el paso del tiempo, las tecnologías que usamos en data & analytics evolucionaron desde aquellas que tenían un propósito general (cuando usábamos una misma herramienta para hacer todo) a herramientas de propósito específico (una herramienta para cada tarea). Es por eso que ya no hablamos de herramientas, sino que directamente nos referimos a stacks tecnológicos.
Para simplificar la complejidad asociada al procesamiento de grandes volúmenes de datos y para dar respuesta a las necesidades de datos que hoy tienen las personas usuarias de negocio, que cada vez demandan más información, no solo tuvimos que repensar la forma de trabajo sino también las herramientas.
Los sistemas distribuidos surgen como una solución a los dos principales problemas que generó el data warehouse: la necesidad de almacenar más información (y más detallada) junto con la lentitud de reacción (en este artículo los explicamos en detalle).
Si bien los sistemas distribuidos datan de los años sesenta, fue en 2009 que surgió el proyecto Spark con el objetivo de resolver el problema de la capacidad de almacenamiento de datos y la capacidad de cómputo, ambas muy restringidas hasta el momento.
¿Cómo funciona un sistema distribuido?
Cualquier sistema distribuido es un conjunto de componentes que permiten almacenar, procesar y administrar recursos. Se dice que tienen una capacidad de almacenamiento y de procesamiento –virtualmente—infinita porque constantemente se pueden agregar nuevos servidores.
Hay dos formas de escalar:
- Vertical: en caso que el servidor necesite más capacidad, se le agrega más memoria, más procesadores o también se puede cambiar el servidor por uno más potente.
- Horizontal: en este caso, lo que hacemos es crear nuevos clusters (que son conjuntos de servidores más pequeños), se trata de agregar un servidor al lado del otro para que trabajen de forma coordinada como si fueran una única máquina.

Computación tradicional vs. computación distribuida.
Veamos esto a partir de un ejemplo: en nuestra empresa solo tenemos un gran servidor y falla. En ese caso nos quedaremos sin nada hasta repararlo o reemplazarlo. Para evitar esto, decidimos tener dos servidores, uno “titular” y otro “suplente”. Esto, a priori, nos resguardaría ante eventuales fallas, sin embargo, tener un servidor de esa magnitud en desuso, sería un desperdicio de capital. Para evitar esto, lo que se puede hacer es poner los dos servidores a trabajar y, en caso de que alguno falle, nos queda el otro. Tiene sentido.
Pero, ¿qué pasa si el negocio empieza a escalar y ya no damos abasto con los dos servidores? Inevitablemente tendremos que comprar un tercer servidor o reemplazar uno de los otros por alguno con mayor capacidad. Recordemos que cada vez que hagamos algún tipo de movimiento con el o los servidores tendremos costos asociados.
En este punto los sistemas distribuidos aparecen como una solución. Pensemos que, si en lugar de tener un solo servidor muy potente tenemos muchos servidores más pequeños, si algo llegara a fallar, muy probablemente no nos enteraríamos ya que la pérdida de capacidad sería marginal. Además, cada uno de ellos tiene un costo mucho menor. Son equipos más normales y eso abarata los costos porque hace que no tengamos que invertir grandes sumas en servidores tan grandes.
Los sistemas distribuidos proponen trabajar por medio de clusters que son conjuntos de servidores que se pueden usar para diferentes propósitos. Este esquema permite:
- Tener una gran tolerancia a fallos.
- Ganar escalabilidad, ya que podemos agregar o quitar equipos según la necesidad.
- Reducir de costos.
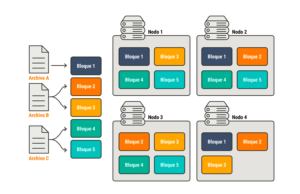
Ejemplo de procesamiento en un sistema distribuido en Hadoop.
Si tenemos, por ejemplo, tres archivos que almacenar, el sistema distribuido los divide y envía cada uno de ellos a un bloque. A su vez, esos bloques los divide en diferentes nodos. Entonces cada bloque forma parte de varios nodos, por ende, si se pierde un nodo, no perdemos información y ahí radica lo más interesante de esta forma de almacenamiento.
De esta manera, los tiempos de lectura son mucho más rápidos y el sistema es más eficiente. Sin embargo, no todo es tan simple ya que administrar y configurar este tipo de clusters es complejo.
La nube nos ayuda a resolver esto al ofrecer el software como servicio (SaaS), de esta manera la complejidad de la configuración no es nuestro problema sino del proveedor de servicios en la nube que utilicemos (Microsoft, AWS, Google, etc.) Nosotros simplemente tenemos que dar instrucciones: qué tipo de cluster necesitamos, qué cantidad de nodos, en qué horario tiene que funcionar, qué storage, etc. De esta manera, con solo algunos clics, ya tendremos el cluster listo para funcionar y lo único que tendremos que hacer es empezar a cargar con datos.
¿Cómo saber qué tipo de sistema distribuido necesito?
Hoy en día hay muchos tipos de sistemas distribuidos. Al momento de evaluar cuál es el más apropiado para la empresa, no hay una respuesta única ya que todo va a depender del tipo de organización, del propósito principal, de los volúmenes de datos, los picos de demanda, etc.
Al momento de empezar a pensar esto, recomendamos responder las siguientes preguntas:
- ¿Cuál es el volumen de los datos que tengo?
- ¿Cuál es el presupuesto disponible?
- ¿Cómo tenemos pensado escalar?
- ¿Cómo serán los ambientes?
- ¿Cómo son los picos de demanda?
- ¿Cuál es el mínimo y el máximo que necesito?
- ¿Tengo restricciones en el tiempo de procesamiento?
- ¿Cuáles son las ventanas de baja demanda?
Definir todo esto al comienzo es clave. Tengamos en cuenta que, después todo esto habrá que administrarlo.
No importa el tamaño de la empresa, hoy cualquiera puede acceder a una capacidad de procesamiento que, antes, estaba reservada para muy pocos. Antes era necesario hacer grandes inversiones, hoy solo necesitamos la tarjeta de crédito, saber configurar el cluster y —lo más difícil— contar con el talento y la visión de negocio necesarios para desarrollar este tipo de proyectos.



